Psicothema was founded in Asturias (northern Spain) in 1989, and is published jointly by the Psychology Faculty of the University of Oviedo and the Psychological Association of the Principality of Asturias (Colegio Oficial de Psicología del Principado de Asturias).
We currently publish four issues per year, which accounts for some 100 articles annually. We admit work from both the basic and applied research fields, and from all areas of Psychology, all manuscripts being anonymously reviewed prior to publication.

Psicothema, 1994. Vol. Vol. 6 (nº 3). 447-463
Juan José López y Manuel Ato
Universidad de Murcia
En este trabajo se revisan los dos procedimientos habituales para el ajuste de diseños multivariantes de medidas repetidas, tradicionalmente denominados Modelo Mixto Multivariante (MMM) y Modelo Doblemente Multivariante (MDM), como generalizaciones de las dos técnicas empleadas en diseños univariantes. Tras una exposición comentada de los paquetes estadísticos que pueden analizar este tipo de diseños y una revisión de los procedimientos analíticos se concluye que SPSS ofrece una información más precisa que BMDP, especialmente en cuanto a los criterios referidos al supuesto de esfericidad multimuestral. Se exponen ciertos detalles que obligan a los usuarios de este paquete a extremar la interpretación de resultados si analizan un diseño de estas características.
Analytical procedures to fitting multivariate repeated measures designs. In this work we review two usual procedures to fit multivariate repeated measures design, the multivariate mixed model approach (MMM) and doubly multivariate model approach (DMM), as a generalization of techniques used in univariate design. We offer a detailed comment of statistical packages using this design (SPSS and BMDP) and we review the analytical procedures of the two methods. We conclude that SPSS provides very detailed results and different sphericity multisampling criteria. Users of BMDP must be then extremely careful interpreting the results of statistical analysis of multivariate repeated measures designs.

Los diseños de medidas repetidas son uno de los instrumentos más utilizados en ciencias del comportamiento. Un seguimiento bibliográfico de su desarrollo analítico nos llevaría a admitir la existencia, primero, de métodos univariantes derivados de la metodología ANOVA y, segundo, de métodos multivariantes como aplicación de la metodología MANOVA, especialmente para subsanar los problemas de esfericidad o circularidad que se plantean en las aplicaciones univariantes. En cualquier caso, la dualidad uni-multivariante se limita exclusivamente al procedimiento analítico y no a la naturaleza multivariante de una situación experimental, en la que se registran distintos criterios para la mejor representación de un constructo. La aplicación de este tipo de diseños (denominados diseños de medidas repetidas doblemente multivariantes) uniría a las ventajas metodológicas de los planteamientos intrasujetos, la flexibilidad y adecuación multicriterio que ofrecen las técnicas multivariantes. No parece, sin embargo, que éste sea un planteamiento experimental de interés para los investigadores de nuestra disciplina, a tenor de lo escaso -más bien nulo- de su uso. Pero no son pocos, curiosamente, los estudios de corte evolutivo o comunitario, en los que en distintas fases temporales (inicio-interfase-foral de un programa de actuación, fases intracurso, etc.) se registran (para los mismos sujetos) distintos indicadores de constructos teóricos. Por tanto, sería lógico analizar todos ellos como una totalidad, y no como múltiples diseños de medidas repetidas o, peor aún, como un modelo MANOVA, que aumentaría innecesariamente la varianza de error en menoscabo de la sensibilidad estadística (Lipsey, 1990).
También es cierto, desde otro punto de vista, que la calidad de los instrumentos estadísticos plasmados en las investigaciones actuales depende, casi exclusivamente, de la familiaridad y accesibilidad que de ellos tenga un investigador (aún a costa de las graves consecuencias que puede suponer el acceso rápido al software estadístico, como bien reflejan Thisted, 1979; Chambers, 1980; Dallal, 1988, 1990 ó Searle, 1989). Y en este punto, tanto la accesibilidad como la familiaridad son escasas. Entre los paquetes más usados sólo BMDP y SPSS incorporan procedimientos ad hoc para este tipo de diseños, si bien las salidas que suministran no se acomodan a formatos convencionales. Por otra parte, la información que se presenta en los textos de más frecuente uso sobre este tipo de diseños, cuando existe, es bastante limitada (p.c. Tabachnick y Fidell, 1989) o no cubre toda la información de los paquetes estadísticos (p.c. Hertzog y Rovine, 1985; Schutz y Gessaroli, 1987).
En este trabajo se presentarán las líneas maestras de los dos procedimientos analíticos aplicables en diseños doblemente multivariantes -modelo mixto multivariante (MMM), y modelo doblemente multivariante (MDM)-, su implantación (para el MMM) en los paquetes estadísticos SAS y SYSTAT y un análisis de las salidas BMDP y SPSS. Y, como también se hiciera en otro artículo de corte parecido (Ato y López, 1992), tomaremos como base un ejemplo multivariante de un diseño mixto con un factor intersujetos y otro intrasujetos, con la garantía de que todo lo expuesto -bajo la perspectiva de la comparación de modelos- podrá generalizarse sin problemas a diseños más complejos.
El problema
Imagínese una investigación en la que un psicólogo está interesado en los resultados de dos procesos terapéuticos distintos aplicados a sujetos depresivos (varones, sometidos a fuertes tensiones laborales, casados y sin hijos), para lo que forma dos grupos de 9 sujetos cada uno. Al primer grupo se le tratará con la terapia A y al segundo con la terapia B. Interesado también en los efectos de los procesos terapéuticos a lo largo del tiempo, nuestro investigador decide registrar medidas de depresión en distintos momentos del período terapéutico, como por ejemplo a los 3, 6 y 9 meses, con la finalidad de detectar posibles variaciones en la tendencia de los efectos de la terapia. Sin embargo, para medir el estado depresivo propone dos criterios distintos basados en manifestaciones conductuales registradas con algún instrumento específico para tal fin. El primero es la valoración efectuada por el cónyuge y el segundo por el mismo sujeto (auto-observación). El conjunto de datos obtenidos tras la fase de tratamiento aparece en la tabla 1.
Damos por supuesto que para nuestro investigador una medida adecuada del estado depresivo no puede limitarse a las manifestaciones conductuales del sujeto o de su cónyuge por separado. Antes bien, debería aunar ambos criterios, lo que supone plantear el diseño de investigación como multivariante, tomando como variables dependientes dos indicadores del constructo «estado depresivo».
Desde otro punto de vista, el hecho de que sea el mismo instrumento el que se administra al mismo sujeto (o a su cónyuge) en tres momentos distintos (3, 6 y 9 meses) define el diseño como de medidas parcialmente repetidas (Arnau, 1986; 1990, Ato, 1991), por la existencia de un factor de agrupamiento intersujetos (terapia A y B). Por tanto, el ejemplo propuesto se resume en un diseño mixto inter-intra multivariante, con dos variables dependientes.
Si el investigador en cuestión desea analizar estos datos encontrará una de estas tres dificultades:
a) los paquetes estadísticos SYSTAT y SAS no recogen ningún módulo o procedimiento específico para el análisis de diseños multivariantes de medidas repetidas, o modelos doblemente multivariantes.
b) BMDP y SPSS, en cambio, ofrecen procedimientos específicos para este tipo de diseños, aunque las salidas que reportan presentan una complejidad notoria en comparación con los diseños univariantes o multivariantes clásicos.
c) Superadas las dificultades de lectura, la información reportada por estos paquetes será diferente. Las salidas -simplificadas- se presentan en las tablas 2 y 3, respectivamente.
A primera vista, la salida del paquete BMDP (tabla 2) es más escueta que la ofrecida por SPSS. En la porción intersujetos se prueba la significación de la constante (GRAND MEAN) y del factor intersujetos o tipo de terapia (A) tanto para las dos variables dependientes de forma conjunta (ALL) como para cada una por separado (VD1: observación cónyuge; VD2= auto-observación). La prueba multivariante utilizada es la T2 de Hotelling (TSQ), aplicable cuando la fuente de variación de interés presenta sólo un grado de libertad (Finn, 1974:152, muestra la aplicación de esta prueba en hipótesis de nulidad de modelos lineales). La prueba F se aplica para los análisis univariantes, siendo SS y MS las etiquetas de las sumas de cuadrados y medias cuadráticas respectivamente.
Para la porción intra (B: tiempo, (B) x (A): interacción terapia x tiempo), el análisis multivariante se basa en T2 (cuando la fuente de variación tiene un grado de libertad), y TZSQ -T Zero S Quared- (Bock, 1985; Timm, 1980) equivalente a la traza de Hotelling-Lawley multiplicada por los grados de libertad del término de error. Además se adjuntan los criterios Lambda de Wilks (LRATIO), Traza de Hotelling-Lawley (TRACE) y Raíz mayor de Roy (MXROOT). En el análisis individualizado de cada variable dependiente se acompañan los índices correctores de Greenhouse-Geisser y Huynh-Feldt (GCI EPSILON y H-F EPSILON) para el ajuste de los grados de libertad de los criterios F.
La salida SPSS (tabla 3) reproduce la mayoría de los resultados de BMDP, si bien se detectan dos tipos distintos de criterios multivariantes para cada fuente de variación de la porción intra (MULTIVARIATE TEST y AVERAGE MULTIVARIATE TEST). Además, se adjunta una prueba de esfericidad (MAUCHLY) y un solo índice corrector de los tipos antes mencionados, aunque con valor claramente distinto.
Las diferencias que puedan existir entre las dos salidas, y que a priori son numerosas, radican en la utilización de procedimientos totalmente distintos para el ajuste de los modelos subyacentes a este tipo de diseños. Por ello creemos conveniente exponer previamente dichos procedimientos presentando, en primer lugar, los equivalentes en modelos de medidas repetidas univariantes como un caso especial de aquéllos.
Diseños de medidas repetidas univariantes
Cuando se utiliza la denominación de diseños multivariantes de medidas repetidas usualmente se hace referencia a uno de dos aspectos distintos:
a) diseños de medidas repetidas sobre una única variable dependiente en los que cada medición se contempla con la entidad propia de una variable dependiente distinta (en nuestro ejemplo el test A se refleja en las variables 3, 6 y 9 meses);
b) diseños de medidas repetidas con más de una variable dependiente.
Sin embargo, el concepto multivariante ha sido sinónimo, al menos en nuestro contexto de trabajo, de multimedida mediante distintos indicadores de un mismo constructo y no tanto como medida repetida de un mismo criterio. Es por ello que en el primer caso el concepto multivariante se refiere a la técnica empleada para el análisis de los datos de un diseño conceptualmente univariante, mientras que en el segundo el concepto multivariante define el propio diseño.
Los modelos de medidas repetidas univariantes, por otra parte, pueden abordarse desde la metodología ANOVA (o modelo mixto), esto es, como un diseño univariante en el que el factor sujeto se codifica como una fuente de variación propia del diseño, o mediante la metodología MANOVA, planteando un modelo multivariante con las diferentes medidas. Aunque el tratamiento de estas perspectivas ha sido abundante en la literatura (Davidson, 1972; O'Brien y Kaiser, 1985: Maxwell y Delaney, 1990; Vallejo, 1991; Amau, 1990), exponemos a continuación los fundamentos básicos de ambas.
La perspectiva del modelo mixto
La primera vía, denominada en lo referente al procedimiento analítico como modelo mixto, exige computacionalmente más recursos que la segunda, puesto que la codificación del factor sujeto amplía enormemente la matriz del modelo; de tal forma que con muestras de sujetos elevadas puede resultar imposible analizar los datos con los paquetes estadísticos actuales. Además, su correcta aplicación exige una forma peculiar de la matriz de varianzas-covarianzas entre las distintas medidas. Rouanet y Lepine (1970) y Huyn y Feldt (1970) han indicado que la obtención de pruebas F no sesgadas requiere la presencia en la matriz de varianzas-covarianzas de un patrón de esfericidad, entendido como variación constante de las diferencias entre cada par de mediciones. Mauchly (1940) desarrolló la prueba que lleva su nombre para verificar la hipótesis de esfericidad de la matriz de varianzas-covarianzas, distribuida según χ2. Niveles de significación altos de esta prueba conducirían al rechazo de la hipótesis de esfericidad.
Un caso particular del patrón de esfericidad es el patrón de simetría combinada, en el que se cumple, por separado, tanto el supuesto de homogeneidad de varianzas como el de covarianzas. El incumplimiento de cualquiera de estos dos supuestos, y por tanto del patrón de simetría combinada, potenciaría también la obtención de pruebas F sesgadas. En este punto, sin embargo, los índices correctores de los grados de libertad desarrollados por Greenhouse y Geisser (1959) y Huynh y Feldt (1976), entre otros, permiten modificar la distribución del criterio F para acomodarlo a la condición particular del patrón mostrado (véase Huynh, 1978: Boik, 1981; Barcikowsky y Robey, 1984, para un uso diferencial de estos índices).
En cuanto a los aspectos analíticos, mediante el enfoque mixto son necesarios -para un factor inter y un factor intra en el caso univariante- un modelo intersujetos:
y = k + A + S(A) (1)
y un modelo intrasujetos:
y = k + A +S(A) + B + A * B (2)
donde y(Nx1) es el vector de los valores de la variable dependiente, k(Nx1) un vector constante (de unos). A(Nx(a-1)) una matriz codificada para el factor inter, S(A) (Nx(n-1)a) una matriz codificada para el anidamiento de los sujetos en el factor inter, B(Nx(b-1)) una matriz codificada para el factor intra B y A * B(Nx(a-1) (b-1)) una matriz concatenada de los vectores de A y B, siendo N el total de observaciones efectuadas (n * b), a el número de niveles del factor inter, b el número de niveles del factor intra y n el número de sujetos por bloque. Si en el diseño se ha contemplado alguna covariante, la naturaleza de los modelos será diferente, especialmente si ésta no es constante entre los distintos tratamientos del factor intrasujeto. Véase a este respecto una formulación más general en Ato y López (1992).
Con el primer modelo se contrasta el efecto de la fuente de variación intersujetos (A) tomando como término de error de la hipótesis el componente S ( A ). Con el modelo intrasujetos, por su parte, se contrastan las fuentes de variación afectadas por el factor intra: B y A* B, tomando como error el propio del modelo expresado en (2), B * S (A).
En cualquier caso, las pruebas F obtenidas deberán ser cautelosamente interpretadas en función de los criterios de esfericidad y simetría combinada antes mencionados.
La perspectiva del modelo multivariante
La segunda vía, que suele referenciarse como modelo multivariante, analiza en conjunto la matriz de varianzas-covarianzas de las distintas mediciones de la variable dependiente. Con este procedimiento se evitan los dos inconvenientes principales del modelo mixto, puesto que no es necesario codificar el factor sujeto y tampoco necesita cumplir supuesto alguno de esfericidad.
El proceso básico más simple para el análisis mediante el modelo multivariante pasa también por la especificación de dos modelos (asumiendo un diseño de medidas parcialmente repetidas). Para la porción intersujetos se plantea un modelo univariante, tomando como variable dependiente el vector v, resultante de:
![]() (3)
(3)
donde 1b es un vector columna de b unos. Para la porción intra se plantea un modelo multivariante tomando como variable dependiente la matriz V, resultante de:
V = Y T (4)
donde T(bx(b-1)) es una matriz de codificación ortonormal que representa las b-1 tendencias exhibidas por los datos de Y en las b medidas repetidas.
En ambos casos, el modelo será:
v (ó V) = k + A (5)
si bien, en el caso intrasujetos, una representación ilustrativa del modelo sería:
V = k + A = (1 + A) B = B + A * B (6)
lo que indica que la hipótesis de nulidad sobre la constante prueba la significación del factor intrasujetos, y la hipótesis sobre el factor inter prueba la significación multivariante de su interacción con el factor intrasujetos.
En cualquier caso, todo contraste multivariante se efectúa en función de una matriz de hipótesis H y una matriz de error E. Desde una perspectiva de comparación de modelos, la matriz E es la matriz de SC de error para el modelo multivariante, y la matriz H el incremento percibido en E cuando se elimina del modelo el componente de interés. Los criterios estadísticos para indicar la relevancia de este incremento son función de ambas matrices; lambda de Wilks, traza de Pillay y de Hotelling-Lawley o raíz de Roy son los más usuales, aunque en el apartado ilustrativo posterior sólo haremos referencia al primero de ellos, definido como:
![]() (7)
(7)
Este criterio se aproxima a la razón F por medio de la transformación (Rao, 1973):
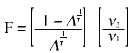 (8)
(8)
que se distribuye aproximadamente según F con v1 = pq y v2 = rt - 2u grados de libertad, siendo:
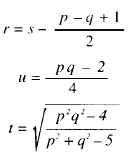 (9)
(9)
donde s representa los grados de libertad de la suma cuadrática residual; p es el número de variables dependientes y q los grados de libertad de la fuente de variación de interés.
El tratamiento analítico de diseños con más de un factor intra puede plasmarse en tantos modelos multivariantes como componentes intra (incluyendo interacciones) se hayan especificado. Cada modelo multivariante precisará una matriz T, de codificación ortonormal de la fuente de variación respectiva, para la obtención de V.
Diseños de medidas repetidas multivariantes
Cuando en el diseño propuesto se incluye más de una variable dependiente, el modelo multivariante que resulta es una generalización lógica del modelo univariante. Dado que este último puede ser abordado mediante el modelo mixto y el modelo multivariante, la generalización a que nos referimos podrá ser tratada mediante el modelo mixto multivariante (MMM) o el modelo doblemente multivariante (MDM). La etiqueta doblemente hace aquí referencia al tratamiento multivariante del diseño, por un lado, y a la especificación de más de una variable dependiente, por otro.
Bajo el MMM, el procedimiento analítico no difiere de un MANOVA convencional y requiere, como en el caso univariante, la especificación de dos modelos si se han incorporado al diseño fuentes de variación intersujetos (uno en caso contrario). Para la porción inter:
Y = k + S + S (A) (10)
y para la intra
Y = k + A + S(A) + A * B (11)
donde Y(Nxp), es la matriz que contiene las N observaciones en las p variables dependientes. La significación de las fuentes de variación se efectúa de igual forma que el caso intersujetos, con la salvedad de que la matriz H*(pxp) representará la matriz de sumas de cuadrados asociadas con la fuente de variación a probar y E*(pxp) la matriz de sumas de cuadrados de error para dicha hipótesis.
Los criterios estadísticos para verificar la nulidad de la fuente de variación implicada son también los usuales en modelos MANOVA. Sin embargo, las mismas puntualizaciones efectuadas en el caso univariante son extensibles al caso multivariante. Esto es, las pruebas estadísticas utilizadas, y en concreto la derivación del criterio F a partir de los criterios multivariantes, serán sesgadas cuando no se cumpla el supuesto de esfericidad conjunta entre todas las variables dependientes (Thomas, 1983; Boik, 1988). Para verificar, entonces, la adecuación del MMM para el análisis de los datos será necesario probar la hipótesis de esfericidad, mediante la generalización de la prueba de Mauchly al caso multivariante, o corregir los grados de libertad mediante las generalizaciones de los correctores antes citados.
Por su parte el MDM ofrece idénticas ventajas que las obtenidas en el caso univariante: evitar la codificación del factor sujeto y eludir el requisito de esfericidad. El procedimiento analítico requiere una matriz Y(nx(bxp)) de medidas en cada uno de los b momentos para cada una de las p variables dependientes. La disposición precisa de esta matriz Y requiere que los b primeros vectores correspondan a la 1.ª v.d., los b siguientes a la 2.ª, etc.
Por último, para la porción intersujetos se planteará un modelo multivariante tomando como variables dependientes la matriz W, definida como:
![]() (12)
(12)
donde Ip es una matriz identidad de dimensión
p y ![]() el producto de Kronecker. Para la porción intra, la matriz Z representa
el conjunto de variables dependientes, según la expresión:
el producto de Kronecker. Para la porción intra, la matriz Z representa
el conjunto de variables dependientes, según la expresión:
Z = Y ( Ip ![]() T ) (13)
T ) (13)
siendo, pues, los modelos inter ó intra:
W ó Z = k + A (14)
advirtiendo aquí también la puntualización efectuada en (6).
Desarrollamos a continuación el ejemplo propuesto mediante ambos métodos.
Modelo Mixto Multivariante
Para los datos de la tabla 1, el factor de clasificación (terapia -A-), el factor sujeto anidado en el factor de clasificación (S (A)), el factor de medidas repetidas (B) y la interacción inter-intra (A*B) deberán ser adecuadamente representados en vectores mediante codificación de efectos, con tantos vectores como grados de libertad estén asociados a cada fuente de variación (1, 16, 2 y 2 respectivamente).
Una forma intuitiva de seguir el procedimiento analítico, sin la necesidad de cálculos matriciales complejos (en especial para el contraste de hipótesis) la ofrece el algoritmo SWEEP (Beaton, 1964; Goodnight, 1979; López, 1992a, 1992b), que requiere definir una matriz L, en este caso con dimensión (54 x 24), compuesta por los términos k(54x1) (para la constante), A(54x1), S(A)(54x16) B(54x2), A * B(54x2) y las dos variables dependientes Y(54x2). Sea, entonces, M(24x24) la matriz de productos cruzados de L ( M = L'L).
Denominaremos con M1 el residual del modelo intersujetos (ec. 10), y con M2 el correspondiente al modelo intrasujetos (ec. 11). En el primer caso, los elementos o fuentes de variación del componente sistemático del modelo son A y S (A); en el segundo, A, S (A), B y A* B, además del necesario término constante (k). La tabla 4 resume el conjunto de operaciones para el ajuste del modelo que a continuación comentamos. La tabla 5 presenta los resultados multivariantes referidos a MMM y la tabla 6 los univariantes.
En el primer modelo, la eliminación del componente A incrementa el error (M1) en la SC de su hipótesis de nulidad. La eliminación del componente S(A) incrementa igualmente el error (M1) en la SC debida al factor sujetos dentro del factor de clasificación, que es el término de error para probar la significación del factor intersujetos. Aplicando sobre estas matrices la ecuación (7) obtenemos el criterio multivariante Lambda, que convertido a la razón F con 2 y 15 g.l. no parece mostrar diferencias significativas entre los dos tipos de terapia (Λ = 0.907; F2,15= 0.771; p = 0.480), toda vez que se toman conjuntamente los dos indicadores conductuales. Las diagonales de estas matrices contienen las sumas de cuadrados univariantes para cada variable dependiente. Por tanto, pueden obtenerse también los criterios univariantes, con los grados de libertad asociados a las dos fuentes de variación (1,16). Analizadas por separado tampoco se detectan efectos diferenciales para cada indicador conductual en función de la terapia administrada.
En el segundo modelo, siguiendo el mismo criterio anterior, la eliminación de B incrementa el error (M 2 = E * intra) en la SC debida al factor B, o la SC de su hipótesis de nulidad. Tomando conjuntamente las dos v.d. habría que admitir un cambio significativo en los sujetos en función del tiempo (Λ = 0.191; F4,62 = 19.939; p = 0.000). Por separado, la apreciación del cambio es superior en las observaciones efectuadas por el cónyuge (F2,32 = 45.282; p = 0.000) que en la auto-observación (F2,32 = 3.740; p = 0.035).
La interacción A*B no presenta diferencias significativas, practicando el mismo procedimiento (Λ = .940; F4,62 = 0.465; p = 0.742).
Ahora bien, este conjunto de resultados (los referidos a la porción intra) deberá admitirse sólo cuando se pruebe el supuesto de esfericidad. La prueba de Mauchly, a este respecto, puede obtenerse con cualquier paquete estadístico, siempre que se ajuste un modelo con una sola variable dependiente. La generalización al caso multivariante será directa, en función de la expresión:
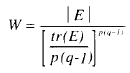 (15)
(15)
donde E es la matriz de SC residuales del modelo intra expresado en (14). Aplicada esta prueba, el valor obtenido es 0.0137, que puede ser transformado a escala χ2 mediante:
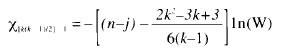 (16)
(16)
donde k = p (q -1) + 1, n es el número de sujetos (18) y j el número de vectores de la porción sistemática del modelo (2: uno de la constante y uno del factor de clasificación), siendo, pues, (n-j) los grados de libertad del componente de error del modelo intra expresado en (14). El valor obtenido, 61.843, con 9 g.l., obliga a rechazar la hipótesis nula del patrón de esfericidad (p = 0.000). Thomas (1983) y Boik (1988) presentan otros criterios -basados en el procedimiento usado por Mendoza et al., 1976- como generalizaciones de la prueba de Mauchly para verificar la esfericidad multimuestral, si bien coincidirían en el incumplimiento del supuesto para estos datos.
Admitido el sesgo de los criterios estadísticos (F), una solución para el MMM (suponiendo normalidad multivariante en los distintos niveles de cada v.d., Winer, 1971) es la aplicación de correctores de los grados de libertad. La generalización del corrector de Greenhouse-Geisser sigue la expresión:
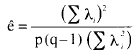 (17)
(17)
donde λi es el i-ésimo eigenvalor de E (matriz de sumas cuadráticas de error del modelo intra expresado en 14). A partir de este dato, la generalización del corrector de Huynh-Feldt viene dada por:
![]() (18)
(18)
El valor obtenido con el primer índice es 0.5044 y con el segundo 0.6135. Cualquiera de ellos permite correcciones en la aproximación al cálculo de la razón F y de sus grados de libertad, modificando los valores q y s según (adaptado de Boik, 1988):
q * = ê
q
s * = ê s (19)
Efectuadas las modificaciones (en las ecuaciones 8 y 9), el valor de F corregido (F*) con el corrector Greenhouse-Geisser para el factor intra (B) pasa a ser 19.307 con 2.02 y 30.28 grados de libertad y una probabilidad asociada inferior a 0.001. Para A*B el valor F* resulta 0.475, con idénticos g.l. y probabilidad igual a 0.628. Mediante la corrección de Huynh-Feldt el valor F* para el factor intra es 19.534 con 2.45 y 37.26 g.l. y probabilidad inferior a 0.001. Para la interacción 0.481 y probabilidad 0.660.
Los criterios F univariantes para las variables dependientes tomadas por separado pueden calcularse mediante las ecuaciones anteriores (con p=1) limitando la matriz E a su i-ésima submatriz [q-1,q-1] (bloque diagonal). En la tabla 6 se presentan los correctores para las pruebas univariantes y sus grados de libertad modificados.
Modelo Doblemente Multivariante
El modelo para el ajuste de la porción ínter (ec. 14) contiene un término constante k(18X1), un vector para el factor de agrupamiento, expresado en codificación de efectos (A(18X1)) , y la matriz de variables dependientes (W(18X2)) definida en (12). La matriz Le contiene estos datos (véase tabla 7), con la que se inicia el procedimiento SWEEP, en la misma secuencia mostrada en la sección anterior, y que se muestra en la tabla 8.
Denominaremos con M3 el residual del modelo inter (ec. 14), o error intersujetos del MDM. La eliminación en el modelo del factor de clasificación determina la SC debida a (A). A partir de este dato, nuevamente detectamos la ausencia de efectos diferenciales significativos en función del tratamiento terapéutico empleado (Λ = .907; F2,15 = 0.771; p = 0.480). Adviértase, sin embargo, que los criterios estadísticos coinciden plenamente con los obtenidos mediante el MMM. La tabla 9 presenta el análisis estadístico para el MDM.
Para la porción intra (véase tabla 7) son necesarios los vectores k y A y la matriz Z de variables dependientes definida en (13), siendo T:
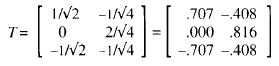
Denominaremos con M4 el residual del modelo intra (ec. 14), o error intersujetos del MDM. La eliminación de la constante determina el incremento debido a la matriz de SC del factor intra, con la que es posible admitir un cambio significativo en los criterios en función del transcurso del tiempo (Λ = 0.058; F4,13 = 53.069; p = 0.000). No se detecta, como también ocurriera en el MMM, una interacción significativa con el tipo de terapia (Λ=0.900; F4,13= 0.361; p = 0.832).
A partir de los datos habría que admitir un efecto diferencial en función del tiempo. Este efecto podemos deducir que es lineal, una vez que se observa un descenso en las medias marginales para las dos variables dependientes. Sin embargo, la verificación estadística de esta suposición implica generalizar el análisis de tendencias del caso univariante al multivariante (multicriterio). Adviértase que Z1 y Z3 (en la tabla 5) son variables transformadas que representan (ec. 13) las tendencias lineales para la primera y segunda variable dependiente, respectivamente. Z2 y Z4 representan sus tendencias cuadráticas. Por tanto, la submatriz generada a partir de la primera y tercera variables dependientes en las matrices que determinan el criterio lambda para B, sirven para probar la tendencia lineal del factor intra; con la submatriz generada a partir de la segunda y cuarta se podrá verificar la tendencia cuadrática. De esta forma, la tendencia lineal exhibida por los datos resulta, precisamente, significativa (Λ = 0.0989; F2,15=68.3595; p = 0.000), afirmación ésta que no puede aplicarse a la tendencia cuadrática (Λ = 0.7035; F2,15 = 3.1613; p = 0.0715).
Comparando los datos de las tablas 8 y 4, puede observarse que para las fuentes de variación intrasujetos (B y A*B), las matrices de hipótesis y de error para el MMM pueden ser extraídas sumando las diagonales de las cuatro submatrices (2x2) obtenidas en el MDM. Timm (1980), con un procedimiento distinto, deduce las matrices para el MMM promediando la suma de estas diagonales. Por ello, en la salida de SPSS se etiquetan los resultados para el MMM con 'AVERAGED Multivariate Tests of Significance'.
Conclusiones
A tenor de los análisis efectuados hay que destacar que los procedimientos analíticos empleados para el ajuste de diseños multivariantes de medidas repetidas son una generalización directa de las dos técnicas empleadas para el ajuste de diseños univariantes, incluso en los supuestos que conlleva cada una de ellas. Por tanto, y en comparación con la oferta de los paquetes estadísticos, habría que realizar ciertas puntualizaciones:
En primer lugar, la información de BMDP es más escueta que la de SPSS, especialmente cuando el componente inter contiene sólo 1 grado de libertad (2 niveles), como ocurre en nuestro ejemplo, reduciéndose entonces el análisis estadístico del MDM a la prueba T2 de Hotelling (TSQ en la sección WITHIN -ALL-. Véase Dixon, 1992: 1286). Además, los índices correctores de Greenhouse-Heisser y Huynh-Feldt se refieren a modelos univariantes (véase tabla 6) por lo que no se dispone de índice alguno que permita corregir el sesgo producido por el incumplimiento del supuesto de esfericidad ni otro criterio con el que validar los datos obtenidos mediante el MMM.
En segundo lugar, SPSS aplica ambos métodos sin limitación alguna. Además, en los resultados obtenidos se advierte la presencia de la prueba generalizada de Mauchly, así como de los índices correctores generalizados. Sin embargo, dado el caso de rechazar el supuesto de esfericidad -como ocurre en el ejemplo analizado- la corrección de los estadísticos F derivados de los criterios multivariantes (tabla 5), queda en manos del usuario, toda vez que no es aportada por el paquete. No obstante, el análisis de este tipo de diseños resulta más completo mediante este paquete, siempre que facilita al usuario la tarea de encontrar una solución adecuada en función de los supuestos inherentes a los modelos.
En tanto a éstos, una estrategia adecuada para la interpretación analítica de diseños multivariantes de medidas repetidas, mediante SPSS, partiría del MMM para llegar al MDM. Esto es, siempre que el criterio de Mauchly no implique ausencia de esfericidad, resulta más potente el análisis del MMM y por tanto más recomendable. En caso contrario, puesto que la corrección de los grados de libertad es ciertamente laboriosa, es preferible adoptar los resultados del MDM.
Al margen de esta cuestión, ninguno de estos paquetes estadísticos parece disponer de los procedimientos necesarios para el análisis de tendencias lineales generalizados al caso multivariante.
Por último, el análisis mediante el MMM podría aplicarse tanto en SAS como en SYSTAT, planteando un modelo multivariante mediante la codificación del factor sujeto. SYSTAT, a este respecto, puede verse más limitado que SAS, puesto que no utiliza inversas generalizadas para solventar el problema de matrices singulares, muy frecuentes en diseños de medidas repetidas (sobre todo en diseños de medidas totalmente repetidas). En la tabla 10 se presenta la secuencia tipo de ordenes para estos paquetes. No obstante, los resultados que puedan obtenerse estarán sujetos al cumplimiento de los supuestos del MMM, que no pueden probarse con estos paquetes. En cualquiera de ellos se formulará un modelo para la porción inter (ec. 10) y otro para la porción intra (ec. 11).
Para probar las fuentes de variación intersujetos se efectuarán hipótesis lineales, tanto para los factores intersujetos como para sus interacciones, tomando como error el factor sujeto anidado dentro de la interacción inter de orden superior.
Para cada fuente de variación intrasujetos también se efectuará una hipótesis lineal. En el caso de especificar más de un factor intrasujetos, el término de error en cada caso será la interacción del factor(es) intra incluido(s) en la fuente de variación con el término de error intersujetos.
Referencias
Arnau, J. (1986). Diseños Experimentales en Psicología y Educación. Volumen II. México: Trillas.
Arnau, J. (1990). Diseños Experimentales Multivariables. Madrid: Alianza.
Ato. M. (1991). Investigación en Ciencias del Comportamiento. I: Fundamentos. Barcelona: PPU/DM.
Ato, M. y López, J. J. (1992). Análisis de covarianza en diseños de medidas repetidas: el riesgo de una interpretación. Anuario de Psicología, 55, 91-108.
Barcikowski, R. S. y Robey, R. R. (1984). Decisions in single group repeated measures analysis: Statistical tests and three computer packages. The American Statistican, 38, 148-150.
Beaton, A. (1964). The Use of Special Matrix Operators in Statistical Calculus. Princeton, NJ: Educational Testing Service.
Bock, R. D. (1985). Multivariate Statistical Methods in Behavioral Research. Reprinted. NY: Scientific Software.
Boik, R. J. (1981). A priori tests in repeated measures designs: effects of nonsphericity. Psychometrika, 46, 241-255.
Boik,R. J. (1988). The Mixed model for multivariate repeated measures: validity conditions and an approximate test. Psychornetrika, 53, 469-486.
Chambers, J. M. (1980). Statistical computing: history and trends. The American Statistician, 34, 238-243.
Dallal, G. E. (1988). Statistical microcomputing: like it is. The American Statistician, 42, 212-216.
Dallal, G. E. (1990). Statistical computing packages: dure we abandon their teaching to others? The American Statistician, 44, 265-266.
Davidson, M. L. (1972). Univariate versus multivariate tests in repeated measures experiments. Psychological Bulletin, 77, 446-452.
Dixon, W. S. (ed) (1992). BMDP Statistical Software Manual. Berkeley, CA: University of California Press.
Finn. J. D. (1974). A General Model for Multivariate Analysis. NY: Holt, Rinehart and Winston.
Goodnight, J. H. (1979). A tutorial on the SWEEP operator. The American Statistician, 33, 149-158.
Greenhouse, S. W. y Geisser, S. (1959). On methods in the analysis of profile data. Psychornetrika, 24, 95-112.
Hertzog, C. y Rovine, M. (1985). Repeated measures analysis of variance in developmental research: selected issues. Child Derelopment, 56, 787-809.
Huynh, H. (1978). Some aproximate tests for repeated measures designs. Psychometrika, 43, 161-175.
Huynh, H. y Feldt, L. S. (1970). Conditions under which mean square ratios in repeat desings have exact F-distributions. Journal of the American Statistical Association, 65, 1582-1589.
Huynh, H. y Feldt, L. S. (1976). Estimation on the Box correction for degrees of freedom from sample data in randomized block and split-plot designs. Journal of Educational Statistics, 1, 69-82.
Lipsey, M. W. (1990). Design Sensitivity: Statistical Power in Experimental Research. Newbury Park, CA: Sage Publications.
López, J. J. (1992a). SWEEP: un algoritmo para la docencia e investigación con modelos lineales. Universidad de Murcia: tesis doctoral no publicada.
López, J. J. (1992b). El algoritmo SWEEP y el modelo lineal general. Anales de Psicología, 8, 139-147.
Mauchly. J. W. (1940). Significance test for sphericity of a normal-n-variate distribution. Annals of Mathematical Statistics, 11, 204-209.
Maxwell, S. E. y Delaney, H. D. (1990). Designing Experiments and Analyzing Data. A Model Comparison Perspective. Belmont, CA: Wadsworth Publishing Company.
Mendoza, J. L., Toothaker, L. E. y Crain, B. R. (1976). Necessary and sufficient conditions for F ratios in the L x J x K factorial design with two repeated factors. Journal of the American Statistical Association, 71, 992-993.
O'Brien, R. G. y Kaiser, M. K. (1985). MANOVA method for analyzing repeated measures designs: an extensive primer. Psychological Bulletin, 97, 316-333.
Schutz, R. W. y Gessaroli, M. E. (1987). The analysis of repeated measures designs involving multiple dependent variables. Research Quarterly for Exercise and Sport, 58(2), 132-149.
Searle, S. R. (1989). Statistical computing packages: some words of cautions. The American Statistician, 43, 189-190.
Rao, C. R. (1973). Linear Statistical Inference and Its Applications. 2nd. Edition. NY: John Wiley & Sons, Inc.
Rouanet, H. y Lepine, D. (1970). Comparison between treatments in a repeated-measurements design: ANOVA and multivariate methods. British Journal of Mathematical arad Statistical Psychology, 23, 147-163.
Tabachnick, B. G. y Fidell, L. S. (1989). Using Multivariate Statistics. 2nd. Edition. NY: Harper and Row.
Thisted, R. A. (1979). Teaching statistical computing using computer packages. The American Statistician, 33, 27-35.
Timm, N. H. (1980). Multivariate analysis of variance of repeated measures. In P. R. Krishnaiah (Ed.), Handbook of Statistics, Vol. 1 (pp. 41-87). NY: North Holland.
Thomas, D. R. (1983). Univariate repeated measures techniques applied to multivariate data. Psychometrika, 48, 451-464.
Vallejo, G. (1991). Análisis Univariado y Multivariado de los Diseños de Medidas Repetidas de una Sola Muestra y de Muestras Divididas. Barcelona: PPU.
Winer, B. J. (1971). Statistical Principles in Experimental Design. 2nd. Edition. NY: McGraw-Hill.
Aceptado el 22 de marzo de 1994