Psicothema was founded in Asturias (northern Spain) in 1989, and is published jointly by the Psychology Faculty of the University of Oviedo and the Psychological Association of the Principality of Asturias (Colegio Oficial de Psicología del Principado de Asturias).
We currently publish four issues per year, which accounts for some 100 articles annually. We admit work from both the basic and applied research fields, and from all areas of Psychology, all manuscripts being anonymously reviewed prior to publication.

Psicothema, 1997. Vol. Vol. 9 (nº 1). 187-197
Concepción San Luis Costas, Juan A. Hernández Cabrera y Gustavo Ramírez Santana
Universidad de La Laguna
En las investigaciones del campo aplicado con técnicas multivariadas es muy frecuente encontrar matrices de datos con valores perdidos. Las estrategias más comúnmente utilizadas para reconducir este problema, utilizan los métodos listwise, pairwise y los de estimación de máxima verosimilitud. En este articulo se demuestra mediante las técnicas de simulación de Monte Carlo en el ámbito de los modelos estructurales, que independientemente del patrón de missing simulado (missing completamente aleatorio, monotónico o condicional) la estimación mediante el algoritmo de máxima verosimilitud EM arroja los mejores resultados, en cuanto a la precisión de la estimación de los parámetros de los modelos, disminución de los errores típicos, y la posibilidad de encontrar soluciones adecuadas y convergentes en aquellos patrones de missing donde las estrategias MCAR (listwise y pairwise) son imposibles de utilizar.
Maximun likelihood missing values estimation in patterns of missing MAR and MCAR in structurals models. In the research’s of the applied field is very common to find matrices of data with lost values. The main strategies used in order to fix this problem, are the methods listwise, pairwise and maximum likelihood estimates. This article shows through Monte Carlo simulation in the field of the structural models, that irrespective of the pattern of missing simulated (missing completely at random, monotonic missing or conditional missing) the estimates through the maximum likelihood algorithm EM throws the better results, concerning the biases in the estimate of the parameters of the models, decrease of the standard errors, and the possibility of finding convergent and adequate solutions in those patterns of missing where the strategies MCAR (listwise and pairwise) are impossible to use.

La inferencia estadística con datos perdidos es un problema muy importante de la investigación aplicada en general y de las investigaciones con modelos estructurales en particular. Básicamente son tres las dificultades fundamentales en el uso de matrices con datos perdidos. En primer lugar, si los casos con "missing" son diferentes a los casos completos, las estrategias comunes de tratamiento de este problema presentan un importante sesgo. En segundo lugar, la existencia de datos perdidos generalmente implica una importante pérdida de información, por lo que las estimaciones de parámetros pueden ser ineficientes. Finalmente, las técnicas estadísticas disponibles están diseñadas para datos completos, por lo que, la sola presencia de datos perdidos perjudica notablemente el análisis (Roderick, Little & Schenker, 1995).
Antes de exponer los métodos disponibles para la estimación de casos perdidos, se hace necesario describir sucintamente los diferentes patrones de "missing" que pueden encontrarse en la investigación aplicada.
Patrones de missing.
Si una matriz es completa (sin casos perdidos), puede ser definida como una matriz X=Xij de orden n x p, de tal forma que Xij es el valor de la variable j, j=1... p en el caso i, i=1 ...n. Si consideramos a la matriz M=mij de orden n x p, como una matriz de indicadores de datos perdidos, de tal forma que mij= 1 si xij es un dato perdido y mij=0 si xij está presente. La matriz M describe el patrón de missing, y su media marginal de columna, puede ser interpretada como la probabilidad de que xij sea missing.
La determinación del patrón de missing presente en los datos, es una tarea de gran interés. Responder a preguntas del tipo. ¿Los sujetos que responden a una determinada variable son en realidad diferentes de los que no responden?. La ausencia de respuesta a una determinada variable, ¿es función de otra variable antecedente? (vg: a mayor nivel socioeconómico, menor índice de respuesta en la variable ingresos brutos anuales). En general, si podemos considerar que la matriz generada mediante los procedimientos listwise o pairwise es una matriz aleatoria de la matriz global, diremos que los datos presentan un patrón de missing completamente aleatorio (missing completely at random , MCAR), o lo que es lo mismo, diremos que el patrón de missing no es función de ninguna variable de la investigación. El patrón MCAR se define finalmente según Rubin (1976) como:
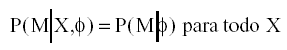
Ec. 1
la distribución
de missing dado X, depende exclusivamente del parámetro ![]() ,
que caracteriza a las respuestas. Esta premisa MCAR puede ser evaluada mediante
el programa BMDPP8 (Dixon, 1988), que arroja valores t, para cada variable,
bajo la hipótesis nula de un patrón univariado de missing completamente
aleatorio. Sin embargo, si este patrón depende de otra variable y de
ésta se dispone de respuesta tanto para los que responden como para los
que no, el sesgo en la estimación de los datos perdidos mediante las
estrategias anteriormente comentadas que exigen un patrón MCAR, puede
ser controlado mediante un análisis que estratifica o ajusta la variable
missing en función de la variable o variables antecedentes correlacionadas
con la variable con ausencia de respuesta, de las cuales se dispone de datos
para todos los sujetos de la muestra. Este patrón de missing se conoce
como valores perdidos aleatorios MAR (missing at random). Se define funcionalmente
como:
,
que caracteriza a las respuestas. Esta premisa MCAR puede ser evaluada mediante
el programa BMDPP8 (Dixon, 1988), que arroja valores t, para cada variable,
bajo la hipótesis nula de un patrón univariado de missing completamente
aleatorio. Sin embargo, si este patrón depende de otra variable y de
ésta se dispone de respuesta tanto para los que responden como para los
que no, el sesgo en la estimación de los datos perdidos mediante las
estrategias anteriormente comentadas que exigen un patrón MCAR, puede
ser controlado mediante un análisis que estratifica o ajusta la variable
missing en función de la variable o variables antecedentes correlacionadas
con la variable con ausencia de respuesta, de las cuales se dispone de datos
para todos los sujetos de la muestra. Este patrón de missing se conoce
como valores perdidos aleatorios MAR (missing at random). Se define funcionalmente
como:
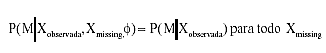
Ec. 2
Es decir, la distribución de los casos perdidos, dado X, depende exclusivamente de la variable Xobservada de la matriz de datos X.
Seguidamente haremos un breve recorrido por las estrategias mas comunes, utilizadas por los investigadores del campo aplicado en el tratamiento de matrices de datos con valores perdidos.
Análisis de casos completos
En este tipo de análisis, el investigador simplemente elimina aquellos casos que presentan datos perdidos en las variables que vayan a ser utilizadas. Es el sistema estandarizado en la mayoría de los paquetes estadísticos comerciales, y se conoce con el nombre de "listwise". Presenta como ventaja fundamental su facilidad de implementación, así como la obtención de estimadores válidos, siempre que el patrón de missing sea completamente aleatorio (MCAR ). En otras palabras, si podemos considerar la muestra de datos incompletos como una muestra aleatoria de la muestra global (sin datos perdidos) (Rubin, 1976). Sin embargo, esta estrategia de análisis pierde una importante cantidad de información directamente proporcional al número de "missing". La solución a este problema de pérdida de información suele radicar en eliminar aquellas variables con un mayor porcentaje de valores missing. En cualquier caso, si el patrón de missing no es MCAR, el tamaño del sesgo depende, entre otros aspectos, del grado de asociación entre la variable missing y otras variables de la investigación, de la cantidad de datos perdidos así como de las características intrínsecas del análisis que se esté llevando a cabo.
Análisis de las respuestas disponibles
El método conocido como "pairwise", constituye otra estrategia muy utilizada. Esta metodología de análisis forma una matriz de varianzas y covarianzas utilizando para ello todos los datos disponibles . De esta forma, los elementos de la matriz de momentos resultante surgen, como es obvio, de diferentes tamaños muestrales, lo cual confiere a esta estrategia un inconveniente fundamental derivado del hecho de que la matriz así obtenida, es frecuentemente no positiva definida, lo que la invalida para ser usada en técnicas estadísticas que requieran la inversión de la matriz de momentos.
Sustitución de los valores perdidos por el valor medio de la variable
Otra estrategia muy común en presencia de matrices de datos, donde la metodología listwise conduce a matrices de varianzas y covarianzas con muy pocos sujetos, consiste en sustituir el valor perdido por la media de la variable que corresponda. Sin embargo, este método presenta más inconvenientes que ventajas, dado que se produce una disminución artificial de la varianza de la variable que se ha imputado, sesgándose por tanto las asociaciones entre las mismas, dando lugar a estimaciones erróneas (Browne, 1982, 1984).
Estimación de Máxima verosimilitud con datos perdidos
La distribución normal multivariada es una premisa básica en la mayoría de las técnicas estadísticas multivariadas, y especialmente en todas aquellas que realizan la estimación de los parámetros de los modelos mediante máxima verosimilitud. Este método de estimación en el entorno de datos perdidos, requiere la especificación de un modelo de la distribución de X y M:
![]()
Ec. 3
donde P(X,θ) representa el modelo de la distribución de la matriz de datos X en ausencia de datos perdidos, P(M|X, ψ) el modelo para los datos perdidos y θ y ψ son parámetros desconocidos. El interés de la estimación, se centra generalmente en la estimación de los parámetros del vector θ, considerando a los parámetros del patrón de missing (ψ) como ignorables. En este sentido, se asume que las filas de X siguen una distribución normal, con media μ y matriz de varianzas y covarianzas Σ( θ (μ,Σ)). Las estimaciones de máxima verosimilitud de θ son los valores que maximizan la Ec. 3. Dado que el patrón de missing se asume MAR y, por tanto, ignorable sólo el término P(X,θ) de la Ec. 3 contribuye a la estimación ML de θ. Consiguientemente esta estimación es realizada sin incluir el modelo que explica el mecanismo subyacente a los datos perdidos. En este sentido, la probabilidad al ignorar el mecanismo missing es la probabilidad de θ en función de la densidad marginal de Xobservada, ignorando la contribución de M al modelo. Rubin (1976) indica que el mecanismo de los datos perdidos es ignorable sí:
a.-) θ y ψ son parámetros distintos, o sea no funcionalmente relacionados.
b.-) El patrón de missing es MAR; es decir, el método de estimación ML con mecanismo missing ignorable, hace depender la estimación de los datos perdidos de las puntuaciones observadas de X.
Esta es una de las particularidades más interesantes de la estimación ML, ya que supera con creces a la estimación basada en el patrón MCAR. El mismo autor, declara que el método ML ignorable es preferible en todos los casos al resto de los métodos presentados y en muchas ocasiones al método ML con patrón de missing definido y por tanto no ignorable ya que: a) la especificación de un modelo adecuado al mecanismo missing presente en los datos, es frecuentemente una tarea imposible. b) Aún cuando a ciencia cierta el mecanismo missing sea no ignorable, el método ML ignorable, puede ser superior a un mecanismo no ignorable mal especificado.
La estimación ML con patrón de missing ignorable más frecuentemente utilizada es el algoritmo EM (Expected-Maximization) (Dempsted, Laird & Rubin, 1977) que maximiza la siguiente función de probabilidad para estimar la matriz de varianzas y covarianzas así como el vector de medias a partir de matrices de datos incompletas.
![]()
Ec. 4
Sea

la probabilidad de ( basada en los datos completos X=(Xobservada, Xmissing). Así en el método de máxima verosimilitud EM, θt es la estimación de θ en la iteración t del algoritmo. La iteración t+1 consiste en un primer paso de esperanza (Expected) y otro de maximización (Maximization). El paso E toma la esperanza de

en función de la distribución condicional de Xmissing dado Xobservada, evaluada en θ = θt. En la práctica el paso E puede ser considerado como un procedimiento de predicción de datos perdidos por el método de regresión iterativa. De hecho, este paso predice los valores perdidos a través de la regresión de las variables missing sobre las variables observadas para cada sujeto de la muestra, con coeficientes β basados en la estimación de esos parámetros en la iteración t. El paso M estima la matriz de varianzas y covarianzas así como el vector de medias, a partir del relleno de los datos missing realizados en el paso E anterior, es decir maximizando el logaritmo de la función (Orchad & Woodbury, 1972, Little & Rubin, 1987, Dixon, 1988, Schoemberg, 1988). Este método asume una distribución normal multivariada de las variables implicadas. Si ésta no fuese una premisa realista por la naturaleza no normal de los datos, Little y Smith (1987) describen una variación del método EM, denominada ER que utiliza la distancia de Mahalanobis para ponderar a la baja la influencia de los valores extremos en la estimación. Esta variación del algoritmo EM es útil cuando EM no encuentra convergencia.
Una vez que se ha estimado el vector de medias y la matriz de varianzas y covarianzas mediante ML, es posible "imputar" los datos perdidos para cada caso utilizando el valor esperado de las observaciones dada la matriz de varianzas y covarianzas y el vector de medias ML. La técnica de imputación, es similar a la generación de puntuaciones factoriales del análisis de componentes principales o ejes principales. Este método, sin embargo, no va a generar una matriz de datos completa con varianzas y covarianzas idénticas a la estimada. Es exactamente el mismo problema que se encuentra cuando se computan las puntuaciones factoriales, dado que la matriz de covarianzas de las puntuaciones factoriales puede no ser la misma que la matriz teórica de los auténticos factores. La solución evidente a este problema, se encuentra en solicitar múltiples imputaciones de los datos. En este sentido Rubin y Schenker (1986, 1987) encuentran que un número de imputaciones igual a 3, es para la mayoría de las ocasiones el mejor, dado que conduce con una mayor probabilidad a los valores reales de los datos perdidos. En cualquier caso, de llevarse a cabo la triple imputación de los datos perdidos, la matriz de datos aparecerá triplicada para cada caso. Su análisis posterior con cualquiera de las técnicas estadísticas disponibles, requerirá la ponderación de cada caso por 1/3. Una vez realizada esta ponderación la matriz de datos puede ser analizada como una matriz completa normal, aunque los errores típicos estimados en cualquiera de las técnicas habrán de ser multiplicados por la raíz cuadrada del número de imputaciones realizadas para obtener así el auténtico valor del error típico estimado en cada caso.
La existencia de datos perdidos es, tal y como hemos indicado, un problema frecuente en la investigación aplicada. En este trabajo, pretendemos evaluar mediante simulación de Monte Carlo, la eficacia de las distintas estrategias examinadas para reconducir el problema de los datos perdidos, y específicamente en el ámbito de los modelos de estructura de covarianza. Esta es una técnica estadística muy difundida, donde es muy frecuente el uso de matrices de varianzas y covarianzas listwise como input, aún cuando el patrón de missing no sea MCAR, lo cual ocurre la mayor parte de las ocasiones.
En el ámbito de los modelos estructurales, se han propuesto otras técnicas para solucionar el problema de los missing, la primera de ellas lleva a cabo la estimación simultánea del modelo a partir de dos grupos (Baker & Fulker, 1983; Allison 1987), el primero de ellos contiene la matriz de varianzas y covarianzas y el vector de medias de los datos sin missing, mientras que el segundo contiene las mismas matrices para los datos con missing, con ceros en los parámetros relativos a las variables con datos perdidos. El problema fundamental de esta estrategia es doble, por un lado, si existen muchas variables con missing será necesario reparametrizar el modelo adecuadamente, lo cual no es una tarea fácil y, por otro, será necesaria una buena aproximación a los parámetros de comienzo para evitar así los problemas de convergencia y de soluciones inapropiadas por estimación de varianzas negativas. La otra estrategia consiste en incorporar los valores perdidos a la función de discrepancia a minimizar, así como al cómputo del vector de gradientes y matriz de segundas derivadas parciales (Lee, 1986). Desgraciadamente, tal incorporación no está actualmente disponible en los paquetes comerciales y exige un trabajo tedioso y complicado por parte del analista de datos.
Método
La presente investigación se realizó a partir de un modelo estructural de 11 variables observables y 5 latentes (3 exógenas y 2 endógenas). En este modelo de la Figura 1 existen 33 parámetros a estimar. Por tanto, es un modelo con (11*(11+1)/2)-33=33 grados de libertad. A partir de la matriz de varianzas y covarianzas poblacional correspondiente al modelo de la figura 1, se generaron 500 muestras de tamaño 300 en 11 variables utilizando el algoritmo de Fleishman (1978) y Vale and Maurelli (1983) según un programa GAUSS (Hernández, J., San Luis, C. & Sánchez Bruno, 1995). A cada una de estas muestras se le aplicó 3 patrones de missing distintos, con un 20% de datos perdidos en cada uno de ellos.
En la Figura 2, pueden verse los distintos patrones aplicados. El primer patrón es completamente aleatorio (MCAR), el segundo es monotónico creciente, es decir a medida que aumentamos el número de la variable observable, disminuye el número de missing por variable. El tercer patrón, de missing condicional, hace inviable la estimación de matrices de varianzas y covarianzas por los métodos listwise y pairwise, dado que si para los sujetos i=1 hasta 10 hay missing en la primera variable, para esos mismos sujetos en las siguientes variables los casos están completos. Una vez aplicadas las tres "máscaras missing" a cada una de las muestras, éstas eran analizadas una a una mediante un paquete de modelos estructurales creado a tal efecto en lenguaje GAUSS (Aptech Systems, 1995) (Hernández, J. Ramírez, G. & Sánchez, A, 1995), primero de forma completa (muestra completa) y luego cada una de las "nuevas" muestras con el patrón de missing simulado, utilizando como matriz de momentos de entrada la matriz de los datos sin missing, la matriz listwise y la matriz de varianzas y covarianzas estimada según el algoritmo EM implementado en el módulo MISS del paquete GAUSS (Schoenberg, 1988).
Resultados
En la Tabla 1 se presentan el valor medio y desviación típica del mínimo de la función de discrepancia (cuyo producto por el tamaño de la muestra da lugar al estadístico χ2) el estadístico χ2 , los índices de ajuste GFI y AGFI (para la estimación ML) y el error cuadrático medio para cada una de las condiciones simuladas. En esta tabla puede verse en primer lugar, que el valor más pequeño de la función de discrepancia, se sitúa como cabría esperar, en la estimación de la matriz de datos sin missing. Sin embargo, este valor ha sido incluido por un interés meramente comparativo con el mínimo de las distintas estrategias utilizadas para solucionar el problema de los datos perdidos en los tres patrones de missing simulados (completamente aleatorio, monotónico y condicional). En este sentido, puede verse que el mínimo de la estrategia listwise, es siempre mayor que el encontrado en la estimación ML independientemente del patrón de missing simulado. Por otra parte, puede observarse que, como cabría esperar, no existe solución listwise alguna para el patrón de missing condicional, consiguiéndose sin embargo el 100% de las soluciones a través de las 500 muestras al utilizar la estimación ML. En la segunda línea de esta tabla, se encuentra el error cuadrático medio para cada una de las condiciones. Nuevamente, el valor más bajo se sitúa en la estimación sin missing, si comparamos este valor con el resto de los errores, vemos que en todos los casos la estimación mediante matrices listwise genera un error considerablemente mayor que el encontrado en la estimación de máxima verosimilitud, los cuales se encuentran muy próximos tanto al valor medio como a la desviación típica de la estimación sin missing.
Con respecto al estadístico χ2, vemos que se encuentra muy próximo al valor esperado de 33 para la media y 8 de desviación típica para la estimación sin missing. Sin embargo, la estimación a partir de una matriz listwise, genera valores superiores al esperado tanto para la media como para la desviación típica tanto en el patrón MCAR como para el patrón monotónico. Aunque hay que considerar que la estrategia listwise, para ambos patrones, genera matrices de varianzas y covarianzas a partir de 86 y 109 casos completos, respectivamente. Con respecto a la estrategia ML, si consideramos al número de sujetos de la muestra como de 300 (sin missing), evidentemente arrojaría valores del estadístico χ2 muy superiores al esperado a pesar de presentar un error cuadrático medio y un mínimo de la función de discrepancia mucho menores que los valores encontrados en la estimación a partir de las matrices listwise. Por este motivo, se ha escogido como indicadores de ajuste mas adecuado, los índices GFI y AGFI independientes del tamaño muestral. Estos indicadores, evidencian valores medios de ajuste óptimos con una gran estabilidad como se evidencia en la escasa desviación típica de los mismos, independientemente del patrón de missing investigado, en clara concordancia con los errores cuadráticos medios encontrados.
En la Tabla 2, se presentan los valores medios de los 33 parámetros estimados para cada una de las condiciones simuladas. En general, si los comparamos con los encontrados para la estimación sin missing, vemos que presentan valores muy próximos a los de referencia. Aunque como es obvio, en el patrón condicional sólo encontramos los referentes a las soluciones provenientes de la estimación de la matriz de varianzas y covarianzas mediante ML.
En la Tabla 3, vemos los errores típicos empíricos (desviación típica cada parámetro estimado en las 500 resplicaciones) y los errores típicos estimados (media de los errores típicos estimados para cada parámetro) a través de los distintos patrones de missing investigados. Si observamos los errores típicos empíricos y estimados para las muestras sin missing, encontramos que ambos son bajos y coinciden (los errores típicos están correctamente estimados). Sin embargo, si los comparamos con los errores típicos de la estimación a partir de listwise en el patrón aleatorio y monotónico vemos que, aunque tanto los errores típicos como los estimados coinciden, éstos son considerablemente mayores conduciendo, por tanto, a valores t de significación de cada parámetro menores a los esperados.
Con respecto a la estimación de máxima verosimilitud, vemos que todos los errores típicos empíricos son claramente menores a los obtenidos con listwise, lo cual concuerda con una estimación mas certera de los parámetros del modelo. Sin embargo, si observamos los errores típicos estimados, vemos que en general éstos son infraestimados, conduciendo a valores t de significación superiores a los que correspondería. Dicha situación, evidentemente, se debe al hecho de que la estimación de los errores típicos en un modelo estructural se lleva a cabo a partir del producto del inverso del tamaño muestral declarado por la raíz cuadrada de los elementos de la diagonal de la matriz hessiana (segundas derivadas parciales) en el mínimo de la función de discrepancia
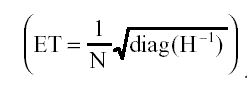
Para todas las estimaciones de ML se ha incluido como tamaño muestral el de la muestra sin missing (N=300). Con la intención de comprobar esta hipótesis, repetimos nuevamente el análisis para la estimación de máxima verosimilitud, en los tres patrones missing incluyendo como tamaño muestral N-20% de los casos (porcentaje de missing de la muestra). En la Tabla 4, puede verse que existe una mayor coincidencia entre los errores típicos estimados y empíricos, lo cual demuestra lo acertado de la solución de disminuir el valor del tamaño muestral eliminando del mismo el porcentaje de missing de la muestra.
Conclusiones
A la luz de la claramente mayor eficacia de la estimación de máxima verosimilitud de las matrices de varianzas y covarianzas (utilizadas en todos las técnicas estadísticas multivariadas), la conclusión obvia de esta investigación recae en el hecho de recomendar la utilización de esta técnica para estimar la matriz de momentos siempre que el investigador se encuentre ante matrices de datos con valores perdidos independientemente de que el patrón sea MCAR o MAR. Tal recomendación se sustenta en el hecho de que aunque la estrategia listwise es suficientemente eficiente en lo que a la estimación de los parámetros se refiere, en patrones missing completamente aleatorios y monotónicos, no lo es tanto en el estadístico de ajuste y en los errores típicos que son claramente más elevados que los de la muestra sin missing, lo que conducirá frecuentemente a la eliminación de parámetros "aparentemente no significativos" del modelo investigado. Por otra parte, el número de soluciones convergentes y adecuadas con esta estrategia es claramente menor al conseguido con la estimación ML. Cuando el patrón de missing es MAR o el número de casos perdidos muy elevado, puede producirse un sesgo en la estimación de los parámetros ya que la matriz muestral listwise no es una muestra aleatoria de la matriz de datos sin missing , o la imposibilidad de estimar el modelo dado que la matriz listwise contiene muy pocos casos. Tal y como hemos podido comprobar, en todas las ocasiones la estimación de máxima verosimilitud fue claramente superior a la realizada a partir de la matriz listwise, y esta estrategia fue imposible de utilizar cuando el patrón de missing era condicional. Hay que indicar, sin embargo, que la estimación ML en este patrón, aunque exitosa en las 500 muestras utilizadas, requirió de un número muy elevado de iteraciones (aproximadamente 200), dado que se utilizó como matriz de comienzo para iterar una matriz identidad de orden p x p (11 x 11).
En el caso de que se necesite disponer de los valores perdidos, y no solamente del vector de medias y de la matriz de varianzas y covarianzas, puede realizarse la triple imputación de los datos perdidos, una vez estimadas las matrices de momentos anteriores por ML, realizando posteriormente la ponderación de los casos por 1/3 para poder llevar a cabo de esta forma los análisis multivariados clásicos con normalidad.
Allison, P.D. (1987). Estimation of linear models with incomplete data. In C.C. Clogg, ed., Sociological Methodology, 1987. Washington, D.C.: American Sociological Association, (pp. 71-103).
Aptech Systems, Inc (1995). Gauss. The Gauss System Version 3.2. Washington.
Baker, L.A. and Fulker, D.W. (1983). Incomplete covariance matrices and LISREL. Data Lanalyst, 1, 3-5.
Browne, M.W. (1984). Asymptotically distribution-free methods for the analysis of covariance structures. British Journal of Mathematical and Statistical Psychology, 7, 62-83.
Dempsted, A.P, Laird, N.M. and Rubin, D.B. (1977). Maximun likelihood from incomplete data via the EM algorithm. Journal of the American Statistical Association, 81, 29-41
Dixon, W.J., ed. (1988). BMDP Statistical Software, Los Angeles: University of California Press.
Fleishman, A.(1978). A method for simulating non-normal distributions. Psychometrika, 43, 4, 521-531.
Hernández, J.; San Luis, C. y Sanchez, J. (1995). Un programa GAUSS para simular distribuciones no normales multivariadas. Psicothema, 7, 427-434.
Hernández, J. Ramírez, G. & Sánchez, A, (1995). A High-level language program to obtain the Bootstrap corrected Adf test statistic. Behavior Research Methods Instruments, & Computer. (En prensa).
Lee, S.Y, (1986). Estimation for structural equation models with missing data. Psychometrika, 51, 93-99.
Little, R.J.A. and Rubin, D.B. (1987). Statistical Analysis with Missing Data, New York: Wiley.
Little, R.J.A. and Schenker, N. (1995). Missing Data. Handbook of Statistical Modeling for the Social and Behavioral Sciences (pp 39-75), New York: Arminger, Clifford, Clogg and Sobel. Plenum Press.
Little, R.J.A. and Smith, P.J. (1987). Editing and imputation for quantitative survey data. Journal of the American Statistical Association, 82, 58-68.
Orchad, T. and Woodbury, M.A.(1972). A missing information principle: theory and applications, Proceedings of the Sixth Berkeley Symposium on Mathematical Statistics and Probability, 1, 697-715.
Rubin, (1976). Inference and missing data. Biometrika, 70, 41-55.
Rubin, D.B. and Schenker, N. (1986). Multiple imputation for interval estimation from simple random samples with ignorable nonresponse. Journal of the American Statistical Association, 81, 366-374.
Rubin, D.B. and Schenker, N. (1987). Interval estimation from multiply-imputed data: A case study using census agriculture industry codes. Journal of Official Statistics, 3, 375-387.
Schoenberg, R. (1988), MISS: A Program for Missing Data, in GAUSS Programming Language, Aptech Systems Inc., P.O. Box 6487, Kent, WA 98064.
Vale, D., & Maurelli, V. (1983). Simulating multivariate nonnormal distributions. Psychometrika, 48, 3, 465-471.
Aceptado el 3 de mayo de 1996