Psicothema was founded in Asturias (northern Spain) in 1989, and is published jointly by the Psychology Faculty of the University of Oviedo and the Psychological Association of the Principality of Asturias (Colegio Oficial de Psicología del Principado de Asturias).
We currently publish four issues per year, which accounts for some 100 articles annually. We admit work from both the basic and applied research fields, and from all areas of Psychology, all manuscripts being anonymously reviewed prior to publication.

Psicothema, 2000. Vol. Vol. 12 (Suplem.2). 87-90
Roser Bono y Jaume Arnau
Universidad de Barcelona
El análisis de series temporales (AST) constituye un procedimiento adecuado de análisis para diseños de series temporales interrumpidas (DSTI). La principal desventaja de esta técnica de análisis es que requiere un número elevado de observaciones con objeto de identificar el correspondiente modelo ARIMA (autorregresivo integrado de medias móviles). Sin embargo, en investigación conductual aplicada la mayoría de diseños tienen muestras pequeñas. Como alternativa al AST, cabe la posibilidad de recurrir a los enfoques de mínimos cuadrados generalizados (MCG). El principal inconveniente cuando se aplica el enfoque de MCG es la estimación de la matriz de variancias y covariancias de los residuales. Por este motivo, en el presente trabajo se estudia un nuevo procedimiento de MCG propuesto como solución alternativa al análisis de datos de series temporales cortas con una sola unidad y dos fases (Arnau, 1999). Se trata de aplicar el criterio de mínimos cuadrados ordinarios (MCO), transformando los datos originales y la matriz del diseño mediante la raíz cuadrada o factor Cholesky de la inversa de la matriz de covariancia, asumiendo que la serie sigue un modelo estacionario autorregresivo de primer orden (Fox, 1997). En este estudio se presenta, mediante simulación Monte Carlo con el programa MATLAB (versión 5.2), la bondad del procedimiento propuesto.
Designs of small samples: Analysis by generalized least squares. The time series analysis (TSA) constitutes an appropriate procedure of analysis for interrupted time series designs (ITSD). The main disadvantage of this analysis technique is that it requires a high number of observations with object of identifying the corresponding ARIMA model (autoregressive Integrated Moving Averages). However, in applied behavioral investigation most of designs have small samples. As alternative to the TSA, it is possible to appeal to the aproaches of generalized least squares (GLS). The main problem for the aplication of GLS approach is the estimate of the residual variancie-covariance matrix. For this reason, in the present paper a new procedure of GLS is studied, it is proposed as alternative solution to the analysis of data of short time series with a single case and two phases (Arnau, en prensa). It is to apply the approach of ordinary least squares (OLS), transforming the original data and the design matrix by the square root or Cholesky factor of the inverse of the covariance matrix, under the assumption of first order autoregressive stationary model (Fox, 1997). In this study is presented, by a Monte Carlo simulation using the MATLAB program (version 5.2), the goodness of the proposed procedure.

Un problema que, a partir de la década de los setenta, se plantea a la metodología de investigación comportamental es el de la inferencia del impacto o efecto de los tratamientos. En especial, cuando se trata de analizar datos de DSTI, dentro del contexto del análisis conductual aplicado. Si bien inicialmente se utilizaron las técnicas estadísticas convencionales, cada vez es mayor la evidencia según la cual esta clase de datos tiene residuales altamente correlacionados y, por lo tanto, las estimaciones de la variancia del error están sesgadas. En tal caso, la violación del presupuesto de independencia de los componentes del error invalida la aplicación de los estadísticos habituales t y F, de manera que cuando la autocorrelación es positiva, la prueba estadística está positivamente sesgada, es decir, es más liberal, y cuando la autocorrelación es negativa, la prueba se vuelve más conservadora (Scheffé, 1959). Así, pues, la presencia de dependencia serial o autocorrelación no hace aconsejable la aplicación de los estadísticos inferenciales clásicos.
Durante los años setenta muchos autores defendieron el AST, desarrollado por Box y Jenkins (1970). Este procedimiento permite eliminar, a nivel estadístico, el efecto de la dependencia serial inherente a los datos. Sin embargo, el AST tiene dos grandes inconvenientes. Por un lado, es necesario una gran cantidad de observaciones para una correcta identificación del modelo ARIMA. El enfoque Box-Jenkins establece un mínimo de 50 observaciones antes de la intervención y otras 50 después de ella. Desafortunadamente, la mayoría de investigaciones dentro del contexto aplicado no satisfacen este mínimo. En segundo lugar, la correcta identificación del modelo requiere grandes conocimientos matemáticos, lo que supone un obstáculo para muchos investigadores.
Debido, por tanto, a que dentro del ámbito conductual aplicado, los datos se comportan como series temporales cortas, es necesario hallar un tratamiento estadístico especial. Por este motivo, una línea de investigación que empezó a tener relevancia a partir de la década de los ochenta, consiste en presentar, dentro de la perspectiva del análisis de series temporales, procedimientos alternativos que tengan en cuenta la dependencia serial y no requieran gran cantidad de observaciones. En esta dirección hay una serie de trabajos que plantean alternativas basadas en el enfoque de MCG (Algina y Swaminathan, 1977, 1979; Simonton, 1977; Swaminathan y Algina, 1977; Velicer y McDonald, 1984, 1991). El enfoque MCG consiste en transformar las observaciones originales para corregir la autocorrelación entre los residuales. Una vez transformados los datos, se estima el efecto de la intervención mediante el criterio de MCO.
El principal inconveniente de la aplicación del enfoque MCG es el cálculo de la matriz de variancias y covariancias de los residuales. Esta matriz incluye en la diagonal principal las variancias de los errores, y en los elementos externos a la diagonal, las covariancias entre los errores en términos de sus retardos en el tiempo. Ello supone la estimación de una gran cantidad de parámetros. Por este motivo, es conveniente asumir alguna restricción a la serie y reducir, de esta manera, la cantidad de parámetros a estimar. Como solución, asumimos que los errores son generados por un proceso autorregresivo de primer orden (Fox, 1997). Así, la matriz de variancia-covariancia residual toma la siguiente forma:
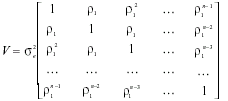
Obsérvese que la matriz V sólo tiene dos parámetros a estimar: la variancia de los errores ( σ2e) y el parámetro de autocorrelación de orden uno (ρ1). Conocidos estos valores, es posible proceder a la estimación por MCG:
![]()
siendo X la matriz del diseño y z el vector de observaciones. De igual modo, se puede aplicar el criterio de MCO:
![]()
transformando los datos y la matriz del diseño mediante una matriz de transformación Γ
![]()
La matriz de transformación Γ es la raíz cuadrada o factor Cholesky de la inversa de la matriz de variancia-covariancia:
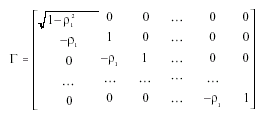
de modo que se cumple la siguiente igualdad:
Γ' Γ = V -1
Este estudio tiene dos objetivos primordiales. En primer lugar, se prueba, mediante simulación Monte Carlo, si la autocorrelación positiva genera un sesgo positivo en el valor calculado del estadístico de la prueba, y si la autocorrelación negativa genera un sesgo negativo. En segundo lugar, se compara, también mediante simulación Monte Carlo, nuestro método con el de Simonton (1977). De este modo, es posible conocer la bondad del procedimiento propuesto y, al mismo tiempo, el efecto de la autocorrelación sobre la estimación del parámetro de la intervención. Más concretamente, sobre su significación estadística.
Estudio Monte Carlo
Método
A través de simulación Monte Carlo, hemos calculado las tasas de error Tipo I y la potencia estadística del criterio MCO y de dos métodos de MCG (Arnau, 1999; Simonton 1977). De esta forma, hemos comparado nuestra aproximación (Arnau, en 1999; Bono, 1999) con el criterio MCO y también con el procedimiento de Simonton (1977) que es uno de los más utilizados dentro del ámbito de la investigación conductual aplicada.
El estudio de simulación se ha llevado a cabo con el programa MATLAB, versión 5.2 (MATLAB, 1998). En primer lugar, con la función rand se generaron los residuales et del modelo autorregresivo de primer orden, con media cero y variancia uno:
zt = ρ1 zt-1 + et
Cada serie temporal simulada empezó con una variable normal z0 con media cero y variancia 1/(1- ρ21) y el resto de observaciones siguen el modelo autorregresivo. Los 30 primeros datos de cada muestra se eliminaron para evitar la dependencia entre ellas (DeCarlo y Tryon, 1993; Huitema y McKean, 1991). En total, se examinaron cinco tamaños muestrales (6, 10, 20, 30 y 50 observaciones), seis valores del parámetro autorregresivo ρ1 (0.9, 0.6, 0.3, -0.3, -0.6, -0.9) y cuatro tamaños del efecto (nulo, cambio de nivel de 1 y cambio de pendiente de 0.3 y 0.6) que se añadieron a cada serie en el punto medio. Para cada combinación se generaron 1.000 muestras. Por lo tanto, la cantidad total de simulaciones para este estudio fue de 120.000.
Resultados
La tabla 1 muestra las tasas de error Tipo I empíricas del enfoque MCO comparadas con las del criterio MCG para los distintos valores de ρ1 y n (Bono, 1999). Las probabilidades empíricas de error Tipo I del enfoque MCO son equivalentes a las de Greenwood y Matyas (1990) y Vallejo (1994). Se observa que el α empírico para valores positivos del parámetro es mayor que el α nominal, es decir, la prueba estadística es más liberal. En cambio, para valores negativos del parámetro, el α empírico es menor que el α nominal de 0.05, es decir, la prueba estadística es más conservadora. La discrepancia entre el α empírico del enfoque MCO y el nominal aumenta conforme el valor del parámetro se distancia de cero, y esta diferencia se acentúa con valores positivos de ρ1 y a medida que n incrementa. De estos resultados se concluye que no es adecuado aplicar a los diseños de series temporales las pruebas estadísticas convencionales t o F que requieren el supuesto de independencia, ya que la autocorrelación sesga sustancialmente los resultados de dichas pruebas. Una solución a este problema es el análisis por MCG.
En términos generales, para valores positivos del parámetro, los procedimientos de MCG corrigen el α positivamente sesgado, particularmente con valores altos de ρ1 . También se comprueba que nuestro método es mejor, puesto que los valores empíricos se aproximan más al nivel de significación nominal para cualquier ρ1 . Esta corrección es mayor a medida que los valores empíricos de α están más sesgados, es decir, para valores altos y positivos del parámetro. Por último, nótese que los dos sistemas de MCG presentan valores empíricos de α similares cuando el parámetro es negativo o para valores bajos de ρ1 .
Junto con la probabilidad asociada al error de Tipo I hemos estudiado la potencia, en función de ρ1, n y del tamaño del efecto (Bono, 1999). Con cambio de nivel de 1 (tabla 2) se observa que, en el enfoque MCO, la cantidad de veces que el valor del estadístico supera el criterio es mayor con valores positivos de ρ1 y menor con valores negativos. Mediante el criterio MCG, se corrige la potencia al eliminar la autocorrelación de los datos. Para ρ1 > 0, la potencia se reduce con relación al modelo de MCO. Por el contrario, para ρ1 < 0, con los procedimientos de MCG hay más potencia que cuando la autocorrelación no está corregida. A su vez, nuestra solución es mejor que la de Simonton (1977) con valores positivos de ρ1, puesto que genera niveles más bajos de potencia, es decir, se corrige el sesgo positivo. En cambio, con valores negativos, es mejor la propuesta de Simonton (1977). En este último caso, la potencia es mayor y, por tanto, queda corregido el sesgo negativo.
La tabla 3 presenta la potencia estadística con cambio de pendiente de 0.3. Al igual que en la tabla anterior, se concluye que nuestra aproximación corrige mejor las autocorrelaciones positivas y la de Simonton (1977), las negativas. Además, se observa que con n ≥ 30, la potencia tiende a aumentar rápidamente a la unidad, tanto para MCO como para MCG. De ello, se concluye que con cambio de pendiente de 0.3, el enfoque de MCG corrige el sesgo existente para tamaños muestrales pequeños. Lo mismo ocurre con cambio de pendiente de 0.6 (tabla 4): cuando ρ1 es positivo, nuestro enfoque corrige mejor el sesgo de la prueba estadística. En este caso, la potencia se acerca a la unidad para n≥20, independientemente del método aplicado (MCO o MCG).
Conclusiones
Por todo lo expuesto, es razonable preguntarse cuáles son las ventajas de nuestro procedimiento (Arnau, 1999; Bono, 1999). En primer lugar, es una variación del método de Simonton (1977) que puede ser aplicado a datos de una sola unidad, aunque también puede aplicarse a diseños de series temporales con múltiples unidades. En segundo lugar, se basa en la factorización Cholesky, de cálculo más sencillo que la transformación generalizada derivada por Velicer y McDonald (1984). En tercer lugar, se trata de un sistema de fácil aplicación con programas de ordenador existentes como, por ejemplo, el MATLAB que permite operar con matrices y, además, tiene incorporado un toolbox de estadística (MATLAB, 1998). Por último, nuestro procedimiento es preferible cuando se trata de corregir el sesgo generado por autocorrelaciones positivas en la prueba estadística, muy común en datos de diseños conductuales. En definitiva, la solución sugerida tiene implicaciones sustanciales para el análisis de series temporales cortas.
Agradecimientos
La investigación ha sido subvencionada por la ayuda PS95-0228 de la Dirección General de Investigación Científica y Técnica, resolución de la Secretaria de Estado de Universidades e Investigación del Ministerio de Educación y Cultura (España).
Algina, J. y Swaminathan, H. (1977). A procedure for the analysis of time-series designs. Journal of Experimental Education, 45, 56-60.
Algina, J. y Swaminathan, H. (1979). Alternatives to Simonton’s analyses of the interrupted and multiple-group time-series designs. Psychological Bulletin, 86, 919-926.
Arnau, J. (1999). Series temporales cortas y mínimos cuadrados generalizados: análisis de la intervención. Metodología de las Ciencias del Comportamiento, 1, 119-135.
Bono, R. (1999). Análisis de series temporales cortas por mínimos cuadrados generalizados: simulación Monte Carlo. Metodología de las Ciencias del Comportamiento, 1, 145-156.
Box, G.E.P. y Jenkins, G.M. (1970). Time-series analysis: Forecasting and control. San Francisco, CA: Holden-Day.
DeCarlo, L. T. y Tryon, W. W. (1993). Estimating and testing autocorrelation with small samples: A comparison of the C-statistic to a modified estimator. Behavior Research Therapy, 31, 781-788.
Fox, J. (1997). Applied regression analysis, linear models, and related methods. Thousand Oaks, CA: Sage.
Greenwood, K. M. y Matyas, T. A. (1990). Problems with the application of interrupted time series analysis for brief single-subject data. Behavioral Assessment, 12, 355-370.
Huitema, B. E. y McKean, J. W. (1991). Autocorrelation estimation and inference with small samples. Psichological Bulletin, 110, 291-304.
MATLAB (1998). The Language of Technical Computing (version 5.2). Natick, MA: The MathWorks, Inc.
Scheffé, H. (1959). The analysis of variance. New York: Wiley.
Simonton, D. K. (1977). Cross-sectional time-series experiments: Some suggested statistical analyses. Psychological Bulletin, 84, 489-502.
Swaminathan, H. y Algina, J. (1977). Analysis of quasi-experiments time-series designs. Multivariate Behavioral Research, 12, 111-131.
Vallejo, G. (1994). Evaluación de los efectos de la intervención en diseños de series temporales en presencia de tendencias. Psicothema, 6, 503-524.
Velicer, W. F. y McDonald, R. P. (1984). Time series analysis without model identification. Multivariate Behavioral Research, 19, 33-47.
Velicer, W. F. y McDonald, R. P. (1991). Cross-sectional time series designs: A general transformation approach. Multivariate Behavioral Research, 26, 247-254.