Psicothema was founded in Asturias (northern Spain) in 1989, and is published jointly by the Psychology Faculty of the University of Oviedo and the Psychological Association of the Principality of Asturias (Colegio Oficial de Psicología del Principado de Asturias).
We currently publish four issues per year, which accounts for some 100 articles annually. We admit work from both the basic and applied research fields, and from all areas of Psychology, all manuscripts being anonymously reviewed prior to publication.

Psicothema, 2002. Vol. Vol. 14 (nº 1). 63-70
Maribel Peró Cebollero y Joan Guàrdia Olmos
Universidad de Barcelona
Actualmente, en el ámbito de la epidemiología, se estudia generalmente las primeras ocurrencias de un trastorno, pero son muchos los trastornos que cursan con más de un episodio. Por esta razón el presente trabajo se centró en el estudio de estos trastornos desde un punto de vista epidemiológico. Para ello se propusieron una serie de indicadores epidemiológicos descriptivos, en concreto la densidad de incidencia y la incidencia acumulada de las recaídas. El estudio de la adecuación de los indicadores propuestos se llevó a cabo vía simulación. Se generaron un total de 32 condiciones diferentes a partir de la manipulación del tamaño de muestra, el periodo de observación, el tiempo en riesgo y la duración de cada episodio. Para cada condición se obtuvieron un total de 100 ficheros de datos. El análisis de los índices obtenidos para estos ficheros mostró que la densidad de incidencia queda influida por el periodo de observación y el orden de la recaída, en tanto que la incidencia acumulada queda influida por el orden de la recaída.
Epidemiological descriptive measures for the study of the relapses. Nowadays, the main aim of epidemiology is the study of the first occurrence of a disorder. But there are a lot of disorders that have more than one occurrence. For this reason this work try to study epidemiologically these disorders. In order to accomplish this objective we carried out a proposal of a sequence of descriptive epidemiological indicators to the study of this phenomenon. These indicators are the incidence density and the accumulated density of relapses. We realised a simulation to study the adequacy of the indicators. We generated 32 different situations by the manipulation of the sample size, the observational period, the risk period and the duration of each episode. For each situation we obtained 100 input data files. The results show that the incidence density is affected by the observational period and the order of the relapse, on the other hand the accumulated incidence is affected by the order of the relapse.

En su origen la epidemiología se ocupó del estudio de las enfermedades de tipo infeccioso, para, con el tiempo, ir abriendo su campo de estudio a todo lo relacionado con el estado de bienestar de los individuos. En consecuencia, actualmente la epidemiología se ocupa del estudio de la fenomenología relacionada con la salud de las poblaciones.
La manera de abordar esta problemática por parte de la epidemiología consiste básicamente en el estudio de la aparición del trastorno bajo estudio (Mac Mahon y Pugh, 1975; Rothman, 1986; Jenicek, M. y Cléroux, R. 1987...). Pero no todos los trastornos cursan con una única ocurrencia en la historia del sujeto que lo padece, a modo de ejemplo, citar la depresión o bien conductas de tipo adictivo (Andrews, 1993, Hinrichsen y Hernández, 1993, Regier et al, 1993, Secades, 1997 y Vázquez y Becoña, 1998, entre otros). Así pues, son diversos los autores que entran en la problemática de cómo se debería afrontar el estudio desde un punto de vista epidemiológico de trastornos que transcurren con más de un episodio. Por ejemplo Norell (1995) y Villalbí Hereter (1995) consideran que en el denominador de la incidencia se puede tener en cuenta el número de episodios en lugar de contabilizar sólo la primera ocurrencia, aunque remarcan el hecho de que los estudios epidemiológicos se suelen limitar al primer episodio del trastorno.
Kleinbaum, Kupper y Morgenstern (1982) o Morgenstern, Kleinbaum y Kupper (1980) proponen estudiar la incidencia de trastornos en sujetos que tienen múltiples episodios ya sea estudiando los episodios por separado o el total de las ocurrencias, aunque, al igual que los autores anteriores remarcan el hecho de que usualmente se trabaja con la primera ocurrencia del trastorno.
Desde un punto de vista aplicado, son diversos los estudios que tienen en cuenta el fenómeno de las recaídas. Algunas de estas investigaciones se limitan a dar el tanto por ciento de sujetos que sufren una recaída, como es el caso de Regier et al (1993) en el estudio de conductas adictivas, esquizofrenias y trastornos afectivos, Lewinsohn, Hops, Roberts, Seeley y Andrews (1993) para el estudio de trastornos de conducta y abuso de sustancias, Tohen, Shulman y Stalin (1994) en el estudio del trastorno maníaco, Hinrichsen y Hernández (1993) en el caso de la depresión mayor o Strober, Freeman y Morrell (1997) en el caso de la anorexia nerviosa, en este último trabajo, los autores también modelizan el proceso a partir de curvas de supervivencia.
En otros trabajos, se propone el uso de los modelos de Markov para el estudio de las recaídas (Tager, 1998). Siendo en las investigaciones de Beckett et al (1996) sobre el cambio de salud a no salud y de Hilton et al (1997) en el estudio sobre episodios de lesiones orales donde se puede ver una aplicación de los mismos.
En otras investigaciones se estudia la asociación entre factores de riesgo y las recaídas del trastorno en cuestión. Entre ellos se pueden citar los trabajos de Fischl, Pitchenik, y Gardner (1981) y de Centor, Yarbrough y Wood (1984) en la aparición de episodios asmáticos, o el de Brown et al (1990) en la ocurrencia de episodios de alcoholismo o el de Simkin y Gross (1994) en el estudio de la conducta sedentaria.
Otra forma de abordar el fenómeno de las recaídas ha sido a través de las técnicas de análisis multivariables. Ya sea a partir del análisis discriminante (Burton y Tillotson 1991), a partir del análisis de supervivencia (Tohen, Tsuang y Goodwin, 1992, Keller, 1994, Fava, Rafanelli, Grandi, Conti y Belluardo 1998, Verheul, Van Den Brink y Hartgers, 1998, Robinson et al, 1999, Stürmer, Glynn, Kliebsch y Brenner, 2000 o Wu, Chen y Lee, 2000), a partir del análisis de supervivencia multiepisodio (Fluke, Yuan y Edwards, 1999) o bien a partir de la regresión logística (Coryell, Endicott y Keller, 1991 o Salive et al 1992).
Por otra parte cabe destacar los trabajos de Ritvo et al (1989) y de Sheldrick, Vernon, Wilson y Read (1992), en los que se plantean algunas propuestas de índices de ocurrencia o de riesgo que tienen en cuenta la repetición del trastorno. Ritvo et al (1989) proponen un indicador de riesgo de repetición del nacimiento de un bebé autista si ya existe uno y un indicador de riesgo de nacimiento de un tercer bebé autista, siendo en este caso la unidad de análisis la familia. Por otra parte Sheldrick et al (1992) proponen un índice de ocurrencia para el caso de solicitar más de una vez atención médica en trastornos oftalmológicos.
Todos estos trabajos ponen de manifiesto la importancia del estudio de trastornos que cursan con más de un episodio en la historia del sujeto que los padece. Pero a la vez muestran la existencia de un vacío en la forma de abordar desde un punto de vista epidemiológico el fenómeno de las recaídas. Es por este motivo que en el presente trabajo se propuso el desarrollo de un índice que tuviera en cuenta la historia completa de trastorno del sujeto, así como el estudio de la adecuación del mismo vía simulación.
Derivación de un índice para el estudio de las recaídas
La derivación de este índice se realizó a partir de la situación más sencilla, a saber, la historia de trastorno de un único sujeto. A nivel esquemático se puede representar a partir del modelo de Andersen-Gill (1982) expresado gráficamente en Moulton y Dibley (1997) o Kelly y Lim (2000):
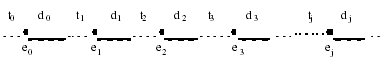
Donde:
ej es el episodio j del sujeto (valores desde j=0 hasta J). Simbolizado por un punto negro.
tj es el momento temporal en el que se inicia el episodio j. Simbolizado por puntos discontinuos.
dj es la duración del episodio j. Simbolizada por una raya continua.
A partir de este esquema se puede observar que el estudio de la ocurrencia de un trastorno que cursa con diferentes episodios se puede abordar desde tres perspectivas:
1. Estudio de la ocurrencia del primer episodio (e0).
2. Estudio de la ocurrencia de las recaídas una vez se ha producido el primer episodio (e1 → ej).
3. Estudio de la ocurrencia de todos los episodios del trastorno (e0 + [e1 → ej])
El estudio única y exclusivamente de las recaídas se debe realizar desde la segunda perspectiva. A partir del esquema anterior, para poder determinar a que velocidad se propagan las recaídas se debe obtener un indicador que dependa del tiempo en riesgo de padecer cada uno de los episodios. El tiempo en riesgo del sujeto i para un episodio cualquiera (j) es:
![]()
y por tanto, el tiempo en riesgo que tenga en cuenta todas las recaídas del sujeto i es el sumatorio del tiempo en riesgo de cada episodio, que queda expresado de la siguiente manera:
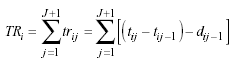
Extrapolando a todos los sujetos, se expresaría como el sumatorio del TRi del total de sujetos, y que se formula como:
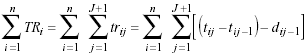
siendo éste el denominador de la densidad de incidencia para las recaídas que se producen en un trastorno para el total de sujetos que padecen dicho trastorno, mientras que el numerador representa el sumatorio de las recaídas de todos los sujetos, y por tanto la densidad de incidencia de las recaídas se expresaría como:
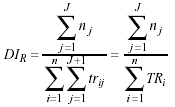
donde nj es el número de personas que recaen en el episodio j.
Su intervalo de confianza al igual que en el caso de la densidad de incidencia para una única ocurrencia del trastorno se basa en la aproximación a la distribución normal de una distribución de Poisson (Ahlbom y Norell, 1987). Y que a continuación queda formulado:
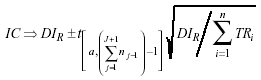
Ahora bien, este índice no es lo suficientemente sensible para diferenciar entre el hecho de que haya muchas recaídas del hecho de que los tiempos en riesgo sean muy cortos, problema que existe también en el caso del estudio de una única ocurrencia del trastorno bajo estudio. Es por esta razón que se consideró necesario obtener otros indicadores además de la densidad de incidencia de las recaídas.
El siguiente indicador a considerar es la incidencia acumulada de las recaídas, es decir la proporción observada de las recaídas, que queda formulada como:
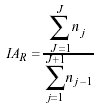
Donde: nj es el número de personas que recaen en el episodio j.
nj-1 es el número total de personas en riesgo de sufrir el episodio j.
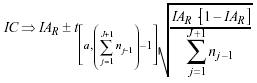
Siendo la condición de aplicación:
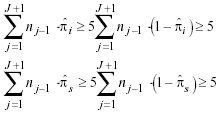
Tanto la densidad de incidencia de las recaídas como la incidencia acumulada de las recaídas son dos indicadores que dependen directamente de todos los factores en los que estén contemplados el tiempo, debido a ello, además de estos dos indicadores también sería conveniente hallar la media de las recaídas, la duración media de las recaídas, el tiempo en riesgo promedio, así como el número total de recaídas, el tiempo en riesgo y el periodo de observación del estudio. Estos indicadores se deben obtener a nivel global y para cada una de las recaídas por separado, por lo que para el estudio descriptivo desde un punto de vista epidemiológico de un trastorno que cursa con recaídas se dispondría de un cuadro resumen como el que se muestra en la tabla 1.
Método
Dado que los dos nuevos indicadores epidemiológicos propuestos para el estudio de las recaídas, la densidad de incidencia y la incidencia acumulada, dependen directamente del factor tiempo, tal y como ya se ha comentado, y los otros indicadores son índices suficientemente conocidos el estudio empírico vía simulación se realizó sólo para la densidad de incidencia y la incidencia acumulada de las recaídas.
Procedimiento
El análisis empírico para el estudio de la adecuación de la densidad de incidencia y de la incidencia acumulada de las recaídas se llevó a cabo en tres fases:
• Generación de ficheros de datos.
• Obtención de la densidad de incidencia y la incidencia acumulada de las recaídas y para cada recaída por separado.
• Análisis de las distribuciones de los indicadores obtenidos.
Las dos primeras fases se llevaron a cabo a partir de dos programas elaborados «ad-hoc» en lenguaje de programación Turbo Pascal (versión 7.0).
La generación de los ficheros de datos se hizo bajo el supuesto de trabajar con población cerrada ya que facilitaba la obtención de los mismos. Otra cuestión a considerar fue el número de recaídas por sujeto, que se generó aleatoriamente a partir de la función «random(n)» de la librería del Turbo Pascal v 7.0 (1993), con un máximo de cuatro recaídas por sujeto, ya que se consideró que era un número suficientemente alto como para poder estudiar el fenómeno de las recaídas.
La generación de estos ficheros se realizó a partir de la manipulación de diferentes parámetros que se consideró podían influir en el cálculo de los indicadores propuestos. Por una parte se trabajó con dos niveles del tamaño de muestra (n = 100 y n=1000). Además se manipularon todos los parámetros que aparecen en el modelo de Andersen-Gill (1982) relacionados con el factor tiempo, el periodo de observación (PO), la duración de las recaídas y el tiempo en riesgo (TR). Con el fin de evaluar la influencia de la longitud del periodo de observación se trabajó con dos niveles del mismo, PO = 547 días y PO = 1095 días, para la duración se trabajó con cuatro niveles, en función de la media y de la desviación tipo (µ = 60 - σ = 15, µ = 60 - σ = 5, µ = 20 - σ = 5 y µ = 20 - σ = 1.66) y finalmente para el tiempo en riesgo se trabajó con dos niveles en función de la media y de la desviación tipo del mismo al igual que con la duración (µ = 60 - σ = 10 y µ = 20 - σ = 3.33). Se seleccionaron estos valores de media y desviación tipo para que fueran suficientemente diferentes entre sí pero, a la vez, para que tuvieran cabida dentro de los periodos de observación propuestos.
La duración de los episodios y el tiempo en riesgo de los mismos se generaron siguiendo la distribución normal con los parámetros antes mencionados, utilizando para ello el algoritmo propuesto por Box-Müller (Dagpunar, 1988). Ahora bien, debe destacarse el hecho de que en tanto que la duración de los episodios si que seguía la distribución normal, la del tiempo en riesgo no. Ello es debido al hecho de que se trabajó con población cerrada, en consecuencia todos los sujetos del estudio formaban parte del mismo durante todo el periodo de observación, y por tanto aquellas personas que no tenían ninguna recaída su tiempo en riesgo era igual al periodo de observación, para aquellas que sólo tenían una primera recaída el tiempo en riesgo de sufrir una segunda recaída era igual al periodo de observación menos el tiempo en riesgo y la duración de la primera recaída, y así sucesivamente. Por tanto, el último tiempo en riesgo de cada sujeto en realidad no se generó siguiendo la distribución normal. Como resulta obvio, las distribuciones del tiempo en riesgo por recaídas y a nivel global resultaron ser asimétricas positivas.
La combinación de los diferentes niveles de las cuatro variables manipuladas dio lugar a un total de 32 condiciones, cuya codificación se muestra en la tabla 2. Para cada una de las condiciones se generó un total de 100 ficheros de datos.
Para cada uno de los ficheros de datos generados se obtuvieron la densidad de incidencia y la incidencia acumulada de las recaídas, así como estos indicadores para cada una de las recaídas por separado. La obtención de estos indicadores se realizó, tal como ya se ha dicho, a partir de un programa elaborado «ad-hoc» en lenguaje de programación Turbo Pascal (versión 7.0).
Resultados
Los ficheros de resultados fueron analizados con el paquete estadístico SPSS para Windows versión 8.0.
Además de los parámetros manipulados, para evaluar la adecuación de los indicadores propuestos, también se debía valorar las posibles diferencias existentes a través de las recaídas, por ello se tuvo en cuenta también este factor.
En consecuencia, se llevaron a cabo dos análisis de la varianza de cinco factores, uno para la densidad de incidencia y otro para la incidencia acumulada, de orden 2 x 2 x 4 x 2 x 4 (12800 observaciones). Es decir dos niveles del tamaño de muestra, dos niveles del periodo de observación, cuatro niveles de la duración, dos niveles del tiempo en riesgo y cuatro niveles de las recaídas. Por otra parte debe comentarse que sólo se tuvieron en cuenta en el análisis las interacciones de primer orden, dado que interacciones de orden superior implicarían un modelo poco parsimonioso.
Los resultados obtenidos en el análisis de varianza correspondientes a la densidad de incidencia se muestran en la tabla 3.
Como se observa en esta tabla todas las fuentes de variación resultaron ser estadísticamente significativas a excepción de las interacciones tamaño x duración, tamaño x tiempo en riesgo y duración x tiempo en riesgo. De todos modos sólo existen tres fuentes de variación con una η2 superior a 0.5, que son la constante del modelo (F(1,15953) = 490743.69, p < 0.001), el periodo de observación (F(1,15953) = 58450.376, p < 0.001) y la recaída (F(4,15953) = 7207.771, p < 0.001), con un valor en la medida del efecto de 0.969, 0.786 i 0.644 respectivamente, las cuales se pueden considerar moderadas-altas.
En la figura 1 se muestra una representación gráfica para cada condición de la media de la densidad de incidencia global para los 100 ficheros de datos generados y las medias de las densidades de incidencia de cada una de las recaídas.
En esta gráfica se observa claramente el efecto del periodo de observación, dado que cuanto mayor es éste (condiciones 9 a 16 y 25 a 32) menor es la densidad de incidencia para cada una de las recaídas y la global. Ello es debido al hecho de que el tiempo en riesgo es mayor cuando el periodo de observación es mayor, no se debe olvidar que se está trabajando con población cerrada. Por otra parte en la gráfica también se observa el efecto de la recaída, ya que a medida que aumenta el orden de la recaída la densidad de incidencia disminuye de valor y ello es debido al hecho de que hay menos casos nuevos en cada recaída.
Además debe remarcarse el hecho de que el indicador global es un promedio de las densidades de incidencia a través de las recaídas lo cual evidenciaría la adecuación del mismo como medida de descripción global de la velocidad de propagación de las recaídas.
En la tabla cuatro se muestran los resultados obtenidos en el análisis de varianza referentes a la incidencia acumulada.
Como se observa en esta tabla las fuentes de variación estadísticamente significativas son la constante del modelo (F(1,15953) = 4748648.8, p < 0.001) y la recaída (F(4,15953) = 27113.185, p < 0.001) con una medida del tamaño del efecto de 0.997 y 0.872 respectivamente, que se pueden considerar altas.
En la figura 2 se muestra la representación gráfica de la media de la incidencia acumulada para cada una de las recaídas y para el indicador global a través de las 32 condiciones analizadas.
En esta gráfica sólo se observa el efecto de la recaída, ya que al aumentar el orden de la recaída disminuye el valor de la incidencia acumulada. Ello es debido, al igual que pasaba con la densidad de incidencia, al hecho de que al aumentar el orden de la recaída el número de casos nuevos es menor. Además, remarcar que los promedios de la incidencia acumulada son iguales a través de las condiciones, lo que evidencia la no influencia de los parámetros manipulados.
Por otra parte en esta gráfica también se observa que la incidencia acumulada global es un promedio de las incidencias acumuladas para cada recaída por separado a través de las 32 condiciones analizadas, lo que es una evidencia a favor de que la incidencia acumulada global es un buen indicador resumen para la descripción de la aparición de un trastorno que curse con recaídas.
Discusión
Los análisis realizados mostraron que las distribuciones de la densidad de incidencia y la incidencia acumulada se comportan como se había predicho.
Así pues, en el caso de la densidad de incidencia se observó como ésta depende directamente del periodo de observación así como del orden de la recaída. En consecuencia este indicador está influido claramente por el periodo de observación del estudio. En el caso de la incidencia acumulada sólo resultó ser estadísticamente significativa la fuente de variación correspondiente a la recaída. Este aspecto es totalmente lógico tal y como se generaron los datos, ya que independientemente de todos los parámetros relacionados con el tiempo, periodo de observación, duración media de las recaídas y tiempo en riesgo, se fijó el número máximo de recaídas que podía sufrir un sujeto a cuatro.
En cuanto al hecho de que al aumentar el orden de la recaída disminuya el valor tanto de la densidad de incidencia como de la incidencia acumulada está directamente relacionado con la manera en que se generaron los ficheros de datos. Debe tenerse en cuenta que además de fijar a cuatro el número máximo de recaídas la distribución de esta variable se generó bajo el supuesto de equiprobabilidad para las diferentes recaídas lo que implicaba una menor proporción de casos nuevos en cada episodio.
Debe destacarse el hecho de que el tamaño de muestra utilizado no ha tenido ningún efecto en los dos indicadores analizados, aunque por otra parte esta variable no debería influir en la obtención de los indicadores descriptivos.
También remarcar el hecho de los indicadores globales para la densidad de incidencia y la incidencia acumulada son un promedio de estos indicadores en las diferentes recaídas a través de las 32 condiciones analizadas lo cual mostraría la adecuación de los mismos en la descripción de la aparición de trastornos que cursan con recaídas. De todos modos, en posteriores investigaciones sería conveniente comprobar la adecuación de estos indicadores bajo diferentes condiciones, por ejemplo en el caso de que las densidades de incidencia o las incidencias acumuladas fueran iguales a través de las recaídas, en esta situación si los indicadores globales fueran también iguales a los de las recaídas nos confirmaría la adecuación de los mismos.
El abordaje que se ha propuesto en este trabajo para el estudio de trastornos que cursan con más de un episodio no se limita a proporcionar tantos por ciento de personas que sufren una primera recaída como ocurre en los trabajos de Regier et al (1993), Hinrichsen y Hernández (1993), Lewinsohn et al (1993), Tohen et al (1994) o Strober et al (1997), sino que se han propuesto dos indicadores epidemiológicos, la densidad de incidencia y la incidencia acumulada, para el estudio global de este fenómeno y no única y exclusivamente de la primera recaída. Aspecto que también mejora los indicadores propuestos por Ritvo et al (1989) que sólo proporcionaban el riesgo de repetición de una primera y una segunda aparición del trastorno o el de Sheldrick et al (1992) que sólo tenía en cuenta a nivel global el fenómeno sin desglosarlo para los diferentes episodios, y además sólo proponían para el estudio de las recaídas un indicador similar a la incidencia acumulada.
De todos modos, en este trabajo no se ha tenido en cuenta el estudio de la relación entre los trastornos que cursan con más de un episodio y un factor de riesgo o de protección, como han realizado algunos autores básicamente a partir de técnicas multivariables (Fischl et al, 1981; Centor et al, 1984; Brown et al , 1990; Burton y Tillotson, 1991; Coryell et al, 1991; Salive et al 1992; Tohen et al, 1992; Keller, 1994; Simkin y Gross, 1994; Fava et al , 1998; Verheul et al, 1998; Fluke et al, 1999; Robinson et al, 1999; Stürmer et al, 2000 o Wu et al, 2000). Ahora bien, se han sentado las bases para la realización de estudios de relación. Que por otra parte, se mejoraría con respecto a los trabajos realizados en el hecho de que se tendría en cuenta todos los episodios del trastorno por separado y a nivel global, cosa que ninguno de los trabajos mencionados realiza, dado que básicamente sólo estudian el riesgo de recaer una primera vez.
Para finalizar destacar una vez más la importancia del estudio desde un punto de vista epidemiológico de trastornos que cursan con recaídas. En este trabajo se ha planteado y desarrollado una de las posibilidades de estudio descriptivo de este fenómeno, similar a la que proponían Kleinbaum et al (1982) o Morgenstern et al (1980). Simplemente remarcar el hecho de la necesidad de obtener los indicadores a través de las recaídas por separado y si éstos son iguales entre sí la posibilidad de obtener un único indicador resumen.
REFERENCIAS
Ahlbom, A., y Norell, S. (1987). Fundamentos de epidemiología. Madrid: Siglo XXI.
Andersen, P.K., y Gill, R.D. (1982). Cox’s regression model for counting processes: a large sample study. The Annals of Statistics, 10(4), 1.100-1.120.
Beckett, L.A., Brock, D.B., Lemke, J.H., Mendes de León, C.F., Guralnik, J.M., Fillenbaum, G.G., Branch, L.G., Wetle, T.T., y Evans, D.A. (1996). Analysis of change in self-reported physical function among older persons in four population studies. American Journal of Epidemiology, 143(8), 766-778.
Brown, S.A., Vik, P.W., McQuaid, J.R., Patterson, T.L., Irwin, M.R., y Grant, I. (1990). Severity of psychological stress and outcome of alcoholism treatment. Journal of Abnormal Psychology, 99(4), 344-348.
Burton, A.K., y Tillotson, K.M. (1991). Prediction of the clinical course of low-back trouble using multivariable models. SPINE, 16(1), 7-14.
Centor, R.M., Yarbrough, B., y Wood, J. (1984). Inability to predict relapse in acute asthma. The New England Journal of Medicine, 310(9), 577-580.
Coryell, W., Endicott, J., y Keller, M.B. (1991). Predictors of relapse into major depressive disorder in a nonclinical population. American Journal of Psychiatry, 148(19), 1.353-1.358.
Dagpunar, J. (1988). Principles of random variation generation. New York: Oxford University Press.
Fava, G.A., Rafanelli, C., Grandi, S., Conti, S., y Belluardo, P. (1998). Prevention of recurrent depression with cognitive behavioral therapy. Archives of General Psychiatry, 55(9), 816-820.
Fischl, M.A., Pitchenik, A., y Gardner, L.B. (1981). An index predicting relapse and need for hospitalization in patients with acute bronchial asthma. The New England Journal of Medicine, 305(14), 783-789.
Fluke, J.D., Yuan, Y.T., Edwards. M. (1999). Recurrence of maltreatment: an application of the national child abuse and neglect data system (NCANDS). Child Abuse and Neglect, 23(7), 633-650.
Hilton, J.F., Donegan, E., Katz, M.H., Canchola, A.J., Fusaro, R.E., Greenspan, D., y Greenspan, J.S. (1997). Development of oral lesions in human immunodeficiency virus-infected transfusion recipients and hemophiliacs. American Journal of Epidemiology, 145(2), 164-174.
Hinrichsen, G.A., y Hernández, N.A.(1993). Factors associated with recovery from and relapse into major depressive disorder in the elderly. American Journal of Psychiatry, 150(12), 1.820-1.825.
Jenicek, M., y Cléroux, R. (1987). Epidemiología. Principios, técnicas, aplicaciones. Barcelona: Salvat Editores, S.A.
Joyanes, L. (1993). Programación en Turbo Pascal. Versiones 5.5, 6.0 y 7.0. Madrid: McGrawHill.
Keller, M.B., Yonkers, K.A., Warshaw, M.G., Pratt, L.A., Gollan, J.K., Massion, A.O., White, K., Swartz, A.R., Reich, J., y Lavori, P.W. (1994).Remission and relapse in subjects with panic disorder and panic with agoraphobia. The Journal of Nervous and Mental Disease, 182(5), 290-296.
Kelly, P.J., y Lim, L.L-Y. (2000). Survival analysis for recurrent event data: an application to childhood infectious diseases. Statistics in Medicine, 19(1), 13-33.
Kleinbaum, D.G., Kupper, L.L., y Morgenstern, H. (1982). Epidemiologic research. Principles and quantitative methods. London: Lifetime Learning Publications.
Lewinsohn, P.M., Hops, H., Roberts, E., Seeley, J.R., y Andrews, J.A. (1993). Adolescent psychopathology: I. Prevalence and incidence of depression and other DSM-III-R disorders in high school students. Journal of Abnormal Psychology, 102(1), 133-144.
Mac Mahon, B. y Pugh, T.F. (1975). Principios y métodos de epidemiología. México: La Prensa Médica Mexicana, S.A:
Morgenstern, H., Kleinbaum, D.G., y Kupper, L.L. (1980). Measures of disease incidence used in epidemiologic research. International Journal of Epidemiology, 9, 97-104.
Moulton, L.H., y Dibley, M.J. (1997). Multivariate time-to-event models for studies of recurrent childhood diseases. International Journal of Epidemiology, 26(6), 1.334-1.339.
Norell, S. (1995). Workbook of epidemiology. New York: Oxford University Press.
Regier, D.A., Narrow, W.E., Rae, D.S., Manderscheid, R.W., Locke, B.Z., y Goodwin, F.K. (1993). The de facto US mental and addictive disorders service system. Epidemiologic catchement area prospective 1-year prevalence rates of disorders and services. Archives of General Psychiatry, 50, 85-94.
Ritvo, E.R., Jorde, L.B., Mason-Brothers, A., Freeman, B.J., Pingree, C., Jones, M.B., MacMahon, W.M., Petersen, P.B., Jenson, W.R., y Mo, A. (1989). The UCLA-University of Utah epidemiologic survey of autism: recurrence risk estimates and genetic counseling. American Journal of Psychiatry, 146(8), 1.032-1.036.
Robinson, D., Woerner, M.G., Alvir, J.M., Bilder, R., Goldman, R., Geisler, S., Koreen, A., Sheitman, B., Chakos, M., Mayerhoff, D., y Lieberman, J.A. (1999). Predictors of relapse following response from a first episode of schizophrenia or schizoaffective disorder. Archives of General Psychiatry, 56(3), 241-247.
Rothman, K.J. (1986). Epidemiología moderna. Madrid: Díaz de Santos.
Salive, M.E., Cornoni-Huntley, J., LaCroix, A.Z., Ostfeld, A.M., Wallace, R.B. y Hennekens, C.H. (1992). Predictors of smoking cessation and relapse in older adults. American Journal of Public Health, 82(9), 1.268-1.271.
Secades, R. (1997). Evaluación conductual en prevención de recaídas en la adicción a drogas: Estado actual y aplicaciones clínicas. Psicothema, 9(2), 259-270.
Sheldrick, J.H., Vernon, S.A., Wilson, A., y Read, S.J. (1992). Demand incidence and episode rates of ophtalmic disease in a defined urban population. British Medical Journal, 305, 933-936.
Simkin, L.R., y Gross, A.M. (1994). Assessment of coping with high-risk situations for exercise relapse among healthy women. Health Psychology, 13(3), 274-277.
Strober, M., Freeman, R., y Morrell, W. (1997). The long-term course of severe anorexia nervosa in adolescents: survival analysis of recovery, relapse, and outcome predictors over 10-15 years in a prospective study. International Journal of Eating Disorders, 22(4), 339-360.
Stürmer, T., Glynn, R.J., Kliebsch, U., y Brenner, H. (2000).Analytic strategies for recurrent events in epidemiologic studies: background and application to hospitalization risk in the elderly. Journal of Clinical Epidemiology, 53(1), 57-64.
Tager, I.B. (1998). Outcomes in cohort studies. Epidemiologic Reviews, 20(1), 15-28.
Tohen, M., Tsuang, M.T., y Goodwin, D.C. (1992). Prediction of outcome in mania by mood-conguent or mood-incongruent psychotic features. American Journal of Psychiatry, 149(11), 1.580-1.584.
Tohen, M., Shulman, K.I., y Stalin, A. (1994). First-episode mania in late life. American Journal of Psychiatry, 151(1), 130-132.
Vázquez, F., y Becoña, E. (1998). ¿El hábito de fumar tiene relación con la depresión? Psicothema, 10(2), 229-239.
Verheul, R., Van Den Brink, W., y Hartgers, C. (1998). Personality disorders predict relapse in alcoholic patients. Adictive Behaviors, 23(6), 869-882.
Villalbí Hereter, J.R. (1995). Epidemiología. En J. Sentís, H. Pardell, E. Cobo y J. Canela (Eds.). Manual de bioestadística, (pp. 261-278). Barcelona: Masson.
Wu, T., Chen, T.H., y Lee, T. (2000). Factors affecting the first recurrence of noncardioembolic ischemic stroke. Thrombosis Research, 97(3), 95-103.
Aceptado el 23 de julio de 2001